PLAYWRIGHT USER EVENT 2024
Tal Barmeir: Exciting topic. So Rebecca, can can take this, forward. We have Ole on on the on the call with us. Please go ahead.
Rebecca Villalba: Hi, Ole. Welcome. How are you doing today?
Ole Lensmar: I'm good. Thanks. How are you?
Rebecca Villalba: Perfect. All good. So we're gonna move forward with Ole oon scaling playwright in CI/CD pipelines. I'm gonna give a brief introduction. He started building HTTP XML-based APIs in the late nineties, and has served as a technical lead and CTO at several startups and companies, including Everywhere Software, where he created SoapUI, and then SmartBear software where he oversaw the Swagger ecosystem.
He has constantly pursued his passion for the business of open source and is now very happily working at Kubeshop, striving to build next-generation open source tools and solutions for QA and testing at scale in the cloud native space. Did I miss anything?
Ole Lensmar: No. That was very well put, Rebecca. Thank you.
Rebecca: Perfect. Well, you can continue with your presentation.
Ole: Thank you. Great. Thank you so much. I'm gonna start by attempting to share. Let me see here. Okay. I'm guessing you can see this now.
Rebecca: Yes. We can. Yeah.
Ole: I'm just gonna move stuff around on my screen. My screens. Okay. Great. So thank you so much for having me. I am going to talk a while about running or scaling Playwright in CI/CD pipelines. I think, all of us that are using or is using Playwright at scale and, you know, eventually come to a point or many of us at least where we wanna automate the execution of our tests as part of our build processes. And I'm gonna try to highlight, you know, just a little bit of the basics, a little bit of the, you know, challenges there, and I'm also gonna show a little bit at the end.
So let's just jump straight in. Obviously, happy to take questions and etcetera at the end, or off, you know, asynchronously later. Okay. Cool.
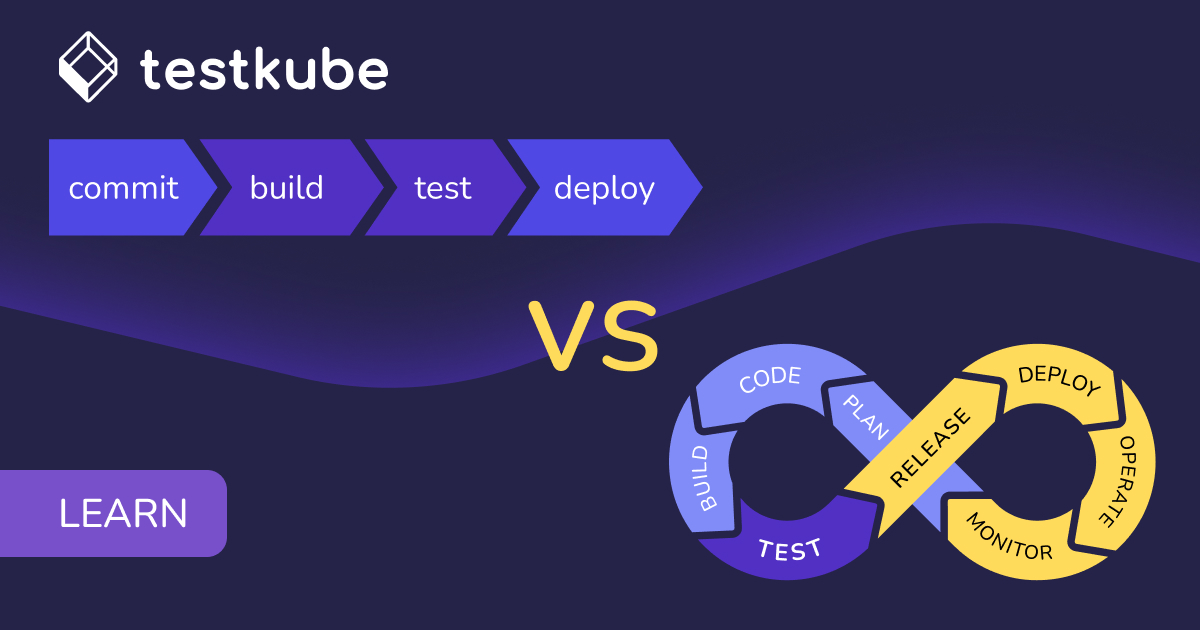
So cluster, level-setting here, what is a CI/CD pipeline? I'm sure most of you know, or have at least, encountered the term.
But just to be on the safe side, so CI–continuous integration–is all about continuously merging or integrating code changes into, from a shared repository and building those artifacts. So if you're building a web application or a microservice and you're you're making some changes, then you wanna automate the build of that microservice and, and may as part of that build, you wanna probably run unit tests and some integration tests. And you might even wanna run some Playwright tests, although that's something that often happens, during the continuous deployment phase depending really on your setup.
But, and where continuous deployment kind of takes off after integration is taking those artifacts, be they a Docker image or a web application that's not in your Docker image, helping you or Lambda functions or whatever, deploying that to their, target architecture and, often, or their target infrastructure. And that could be a staging, infrastructure where it then gets promoted to infrastructure. And that could be a staging, infrastructure where it then gets promoted to production, etcetera. I think the pipelines and the processes around this vary, of course, a lot, depending on the complexity of what you're building and, you know, the the constraints you might have from a legal perspective or compliance perspective, etcetera.
So this is a really, really big and and broad topic. I'm not gonna go too deep, too deep into all the intricacies of CI/CD in itself.
But I'm I'm guessing, everyone has a has a pretty good, familiarity, and you're probably using one or two or maybe even three or four CI/CD tools today. Like, a lot of companies use Jenkins that they've used for a long time, and now they're looking at GitHub actions or maybe ArgoCD for GitOps. And there's often a mishmash of more complex organizations of tools and processes to deliver software.
So next question is why do you wanna run tests in CI/CD? Well, that might also seem obvious.
Well, because as part of, the integration process, you wanna make sure that you don't have any bugs, right, in your software. And that could be, like I mentioned earlier, you wanna catch those bugs as early as possible before they go into production, and those kind of tests could be functional tests like a unit test, like an API test with something like Postman or SoapUI. It could be a UI test or even an end to end test with something like Playwright. But there's also nonfunctional testing that would is relevant to perform.
Right? Performance load testing is maybe not something you do automatically, but compliance testing, security testing, accessibility testing, there's a whole area of other nonfunctional kind of tests that you can run and that you can automate, as part of your CI/CD processes. Obviously, we're gonna focus on Playwright going forward, but I just wanna head that out. And also on the last part here, as much as we love Playwright and automated testing tools, don't forget to also do exploratory and manual testing.
Put some, you know, testers, some smart people at the at your computer, especially if you have a web application and let them go at it, and see if they can provoke errors or bugs or unexpected behavior because, that's that's that's an a skill set and an expertise you don't wanna be, you shouldn't be without, if you're kind of releasing, you know, critical software to your end users.
Running Playwright in CI/CD
Okay. So let's talk about Playwright. So when it comes to Playwright more specifically, the the question is then, when do you run your Playwright tests in the CICD pipeline? So the the obvious thought, I think, will for many will be after you merge or you deploy a new functionality.
Right? So, I've added a new feature. I've deployed that, and I also have a Playwright test that automatically gets kicked in. And then that runs, against the staging or testing environment wherever that has been deployed.
That makes total sense.
Moving one step backwards is running your test as part of your pull or merge requests, meaning, you know, you submit, updates to your application or your microservice, and they're in review. And as part of that reviewing process, you also create an ephemeral or a temporary testing environment for those code changes changes specifically, and you run your tests against that. This requires a little bit more overhead, but it's actually really good if you can, you know, get that infrastructure into place because at the end, you'll make sure that you won't be merging things that, you know, might have, it might break your application. Even if it doesn't go into production directly, it might go into a testing environment or a staging environment where which you're using for other purposes. So, you know, the earlier you can catch errors and fix them, the better in general.
You can, of course, also run your tests more independent of your builds or your build's processes.
Very common, to run your tests maybe on a schedule, like, every hour. I'm gonna get back to that a little bit later later, why you might wanna do that. This, of course, depends on if your CI/CD tool supports that, and you could make the argument that this doesn't really that's not really CI/CD. Right? Because the CI/CD is very tied to the integration of code changes and, deployment of, new artifacts. But when it comes to, you know, reality versus theory, this is actually something that we see a lot, in our users, that preferring to do this. And I will get back to that why.
Another aspect is, should you rerun your tests automatically when the test itself is updated? So as we've seen in by many presenters before, it's right. You have your Playwright project, you're working on your tests, and you maybe you commit that and push that to Git or wherever you're storing it. Should that automatically trigger an execution of your tests?
While there aren't any code changes, maybe that, would suspect you, you might wanna just make sure that when I've updated the test, it actually runs successfully against my staging testing environment, etcetera. So this is something that you have to ask yourself, and one aspect of this is, I'm gonna get out, in just a minute. But, of course, you can combine this in any way of the above of the above. And it's but it's something to be good maybe good to discuss within your team.
Some of the considerations here when you're running playwright tests is that they take time to run and they take resources to run. So, there are some when it comes to if you just need to cut down on execution time, there are some features in Playwright itself that we'll talk about later around sharding and parallelization, that you can do to maybe cut down on execution times.
But, ultimately, if you have a huge end to end test suite that takes ten, fifteen minutes to run because it's very thorough, you do maybe you don't wanna run that for every pull request. Right? This is and this is where, we see people saying, okay. Let's just run this out of bounds, like, once every four hours, against our testing environment because they do, continuous deployment on a daily basis.
So they're they're sure to catch any errors that might go into testing. So this really depends on the complexity and and the resource consumption of your tests. It also you have to consider that some tests require a fixture. Right?
They expect some, you know, they expect some maybe some data to be in your system or they expect the system to return a certain search result or something like that. So you need to make sure to prime the the testing environment with that data.
And what if you're kind of sharing your environments, with your testing environments. So I did mention that you could have an ephemeral environment as part of your merger build process. But if you're doing your tests post merge or post deploy, what if there are multiple tests running at the same time? Could those tests alter the state of your target system that makes them fail, which is not uncommon.
Right? You might have multiple tests modifying a user database, and they're they're just not built for that. And you could, of course, blame it on the tests not being resilient, but you, and try to fix it that way. But at least it's something to be aware of.
And then, of course, there might be other things going on in your system. But what if you're running a load test at the same time, which might be a good thing to do just to make sure that your system is functional under load, but it's also something that could, you know, maybe have side effects on the execution execution times of your load of your functional test, etcetera. So it's it it it it might feel like, I'll just put the Playwright test in my GitHub actions pipeline. But as your application scale and your infrastructure scales and your application scales, and you'll be likely to run into these kind of issues. So as always, it's good to at least discuss them, and maybe go through, like, a checklist or, you know, these things, and then you might decide you will punt on them and, you know, we'll cross that bridge when you get there. But then at least you've acknowledged that there's a bridge to be crossed at some point.
So when it comes to how do you run, Playwright in CI/CD, all modern CI/CD systems have some kind of scripting or configuration based approach, right, to add custom tasks in a pipeline.
So, you know, GitHub Actions has YAML, Jenkins has their pipeline, syntax, which I think is groovy, And others will have, you know, a mix of YAML, JSON, groovy, or others JavaScript, TypeScript, etcetera, which, allows you to kind of inject whatever you might wanna do as part of CI/CD. And the Playwright documentation is great in this far aspect. There's a lot of examples for the most popular, CI/CD systems in there. But what it ultimately boils down to when you write those scripts or configurations, you run Playwright either with NPM, or you run with Docker.
I'm gonna show an example in just a sec. Using NPM is what we saw, people doing earlier is the more lightweight approach, and it's a little bit more configurable. But it does require, it'll reinstall the browser engines manually, and you'll have to make sure that whatever environment your CI/CD system is running in, that it supports those browser engines under that operating system. And it does require more scripting.
It's just more commands, to get it all right. Docker is maybe a more portable and easier way to do this. It'll make it all so much easier to say, you know, I want to run some Playwright tests using a specific version of Playwright. You might have some older tests that you haven't converted to being compatible with a newer version of Playwright.
With Docker, it's super easy to say just, run this version and, and you'll you're sure that you'll get a, you know, a a predictable, environment that your tests are running in. When it comes to Docker, there are some security aspects that, make it not really the right choice if you're using, Playwright for other things than testing. But since we're testing, we're talking about, testing, and maybe not using Playwright for web crawling or other kind of things. I think that's usually not an issue.
But it's something to be aware of. And, once again, the Playwright documentation is really good on kind of teasing out the differences in these two.
GitHub Actions Example: npm vs Docker
Okay. Some code, just to kind of give you an give you an example. I'm I'm hoping or guessing that many of you are familiar with YAML and, and more specifically, GitHub actions.
So this to the left is a GitHub workflow that runs Playwright tests pushing and and pull requests for main and master. And to the left here, we're just using NPM. So you can see that at first, it checks out the repo, and then it runs basically NPM, commands to, set up the CI, for the CI environment for Playwright itself, installs, with dependencies, and then runs the test. And at the end, it actually uploads the artifacts generated.
Over here, you can see the corresponding with Docker. So you'll see that instead of doing the, some of the setup install installation with dependencies, it just uses a a Docker image provided by Microsoft, which contains everything pre-bundled. Right? So and you'll you can be sure that this is gonna run wherever Docker is able to run.
Right? So you don't have to really worry about the constraints of, of your, hosting environment. And as you can also see, it's very target of Playwright. So it would be easy to say, "Hey, I wanna run this with 1.32," for whatever reason. So you just change the number here instead of having to update the commands over here. And you could even parameterize that if you want as part of your workflows.
But, ultimately, in the end, the running the commands is very similar. And although the example to the right doesn't include the uploading reports, it would be a similar approach. So just to show the difference. I personally would recommend Docker, because I I, I prefer the consistency, and the, maybe predictability of that, especially if you have a lot of tests running all the time. I do understand that there's some overhead, related to that. So you, it's it's up to you. Try both, see kind of what works best for you.
Parallelization in CI
Okay. Let's talk a little bit about parallelization.
So Playwright, as you know, I hope, or maybe, has a support for parallel executions, within your, test. Right? So if you have a test, a test that has ten tests, you can ask it to run those tests across two workers, for example, which will then run five tests each. That works fine if those tests are independent or non sequential of each other.
When running under CI/CD, it's actually recommended to not use parallelism, because you wanna prioritize stability and reproducibility for your running tests. Because as soon as you start parallelizing, those those tests are gonna compete for the resources of the node that they're running in.
And, you wanna make sure that those, nodes get full access to resources to run. And it's, it's a straightforward configuration. Right? If you wanna say that under CI, it should always just be one.
And then if it's undefined, which allows you to override them when you're not running under CI. So not a big issue to get set that in place. But what you should be doing instead is using sharding, which is a very cool feature in Playwright, which and that allows you to split up your tests into multiple shards as they call it or groups or I don't know. Well, shards. I'll just stay with that. And then run each shard on a separate node. So, and with separate infrastructure.
So if you look at the this little image here at the bottom, to the left, we have a Playwright job, which is running in one under one host machine with use which is using three workers. So those three workers, which you shouldn't be doing, as I said on the previous slide, will be competing, for resources and will increase the overall execution time because they run at the same time, versus using sharding where you basically split up your tests to run across three independent jobs. And and here you'll you won't get any resource conflicts or contention between those in the since they're running on separate machines, and you'll get a full benefit of having much more infrastructure at your at your fingertips for executing your test.
So if you wanna cut down on execution times or increase coverage. Right? So you could you could use sharding to say, I sharding is very powerful. I'm not going to go into all the details. There's a lot of great examples. But for example, you might want a shard with across browsers. So let's say one shard runs tests with Chromium, the other shard runs with Firefox, the third runs with, you know, whatever else.
And, in that way, you kind of really, allocate full resources to each of them. So it's a very powerful feature worth digging into, and it's which is really great. It's actually not very hard to use. So if you look at how to do this from the command line, you basically run Playwright as before test, and then you specify, shard, which shard of a total.
Right? So let's say I wanna split my tests in four shards. I just say, I want this shard this execution run the first of those four and then this one, the second of those four, etcetera. And the Playwright will do all the magic under the hood.
So if my test contains twenty tests, the first, shard is gonna run the first five, and then the next chart is gonna run the next five. Or if it contains eighteen, the playwright is gonna be smart enough only to give three tests to the last chart. So this is super powerful, and it's super easy to use.
And the the benefits here are you get overall execution times, but there are also some down well, downfalls, things to consider. It does add complexity to reporting, and it does, of course, potentially increase the cost. Right? So depending on the pricing model for your CI/CD system, this might cost more, depending on how they charge for machines ring up. So you'll have to weigh kind of the the, test execution benefits, overall build benefits versus the cost. And that maybe it's worth it, but it's something, worth exploring.
And, of course, this only makes sense if you're using a CI/CD tool that allows you to to kind of distribute shards across nodes.
GitHub does it, and I'm sure many others do it as well, but it's just something that may be worth looking into if you're in the verge of selecting a new CI/CD tool, to and you are using Playwright, you know, checking that we can actually leverage sharding in Playwright in the CI/CD solution you're using, unless you have a third party tool, which I'm gonna get back to.
Sharding with GitHub Actions
Just a quick example here. A lot of YAML here, but but just kind of see how what it looks like. I think maybe the big takeaway is that it's not that hard, to do. You'll see that, in in GitHub actions, you provide a matrix where you, where GitHub has a a matrix functionality where it'll run a sequence of steps for every combination of the values in those matrixes.
So here, these are the shard indexes and the total shard. And then as you can see down here, we're running the Playwright test, which will then run for each index for once. So this will, this will result in four parallel executions being run. Very cool. Something to play around with. And once again, of course, if you're not using GitHub actions, you're using something else. Look look into how they support this.
How to Collect Reports in CI/CD
Okay. So we've talked about running tests in a bunch of different ways. I wanna talk about quickly how to collect reports because that's super important. Right?
We saw in the previous talk, Playwright can can generate these HTML trace reports. It can record videos. It can do screenshots, in your CI/CD system. You'll wanna capture those, and all most CI/CD systems allow you to do that and then upload them to some artifact storage where they're accessible.
So you'll have to add the script to your CI/CD configuration. We saw this earlier. This is how it looks it looks like in GitHub actions, to kind of capture for and you can here you can even set the retention.
One thing to consider is that these artifacts can contain sensitive information. Right? They can the screenshots can contain usernames, or if the logs or the videos or whatever can contain things that maybe not everyone should be seeing. So if if that's the case, make sure that your CI/CD system can kind of either constrain who can look at, these results or maybe, you don't want to save them. Right? Or if there's a way to obfuscate that data, before uploading it. So it this is this could be a big concern, but, it's one of those things that, it's easily forgotten and then somebody looks at the video and they're, why is this Social Security number showing up here in this UI or in this video? And, you know, it might freak some people out even if, maybe it's unlikely that it's gonna so one of once again, security is good to be on top of it instead of doing it later.
When it comes to sharding, just as a side note, when you distribute then your tests across multiple nodes, each of those nodes will have their own report. So but as a tester looking at the reports at the end, you probably want those reports to be merged into one. So let's say you shard your test across ten nodes. You don't wanna have to go to look at ten reports to make sure that everything looks great. Fortunately, Playwright is ahead of us again. So they have great functionality for merging reports into one single report.
And once again, that's something you'll have to script as part of your, CI/CD workflow.
I'll just do another GitHub actions example. I'm gonna rush a little because we're a little bit short of time. But you can see here at the end that, this is triggering the Playwright merge reports, functionality to merge reports that were created across multiple shards or however they were created. Okay.
Challenges with Playwright in CI/CD
So let's jump in a little bit to challenges with Playwright in CI/CD, something to be aware of. So one of them, as you maybe have guessed, it'll be a lot of scripting, whatever CI/CD tool you use. Right? You're gonna end up writing a lot of scripts.
And if you wanna leverage charting and collecting reports and matrix parameters and all of that, over time, this can be a challenge to maintain. Right? So make sure that, you're aware of that and that's it's something you're from of of getting with and that you have allocated time and people to maintain, just like every other code that you have in your infrastructure. Somebody needs to be on top of this and and make sure it, you know, it evolves and it's it's kept in in in shape.
Another is around proliferation of CI/CD tools and practices. I've mentioned earlier, you might start off with one CI/CD tool, but, you know, like, you're in Jenkins or in GitHub actions, but now the ops team wants to introduce ArgoCD or they wanna do Flux or they wanna do something else. So how do you then suddenly the the the scripting kind of doubles. Right?
Now you have to script the execution of your tests in two CI/CD systems or in three CI/CD systems. And how do you make that consistent? How do you make sure that that all works out, efficiently?
Another one is around running tests when needed. It's very common to want to run tests out of bounds of CI/CD workflows. Right? It's great to have your test automated in while you're building or deploying, but you also want to run them, might wanna run them manually. Right? So, hey. I need to rerun this test because we've you know, there was a port cluster, and we couldn't access Stripe. Right? So let's we don't have to do a whole rebuild, redeploy thing. We just press the run button on the test and see how that goes.
Or you might wanna run your tests on schedule like we talked earlier today, and maybe that's not something that your CI/CD system supports. So something to be mindful of that, even if you automate your tests in CI//CD, you might wanna trigger them, not tie them to couple them too tightly to CICD tool.
Another one is around scaling test executions. Right? Like we mentioned, what if you have multiple, multiple teams running tests at the same time or you wanna scale your tests vertically or or, like we said, across multiple nodes? What are the costs of that?
What are the con we talked about conflicts of tests running at the same time. Are you on top are you familiar you know, are are you on top of that? Are you, aware of the effects, or do you do you need some boundaries, set some boundaries, put some boundaries into place saying, you know, we can only you have basically time windows. And we see this at our our customers saying, you know, this team is allowed to run tests on Wednesdays, and that team is allowed to run tests on Thursdays. It sounds very old school and very, clunky, but sometimes that where you end up. Right? Just because you don't wanna be interfering with each other, and and, when it comes to maybe some shared resource.
Test troubleshooting and reporting, we saw that you can collect artifacts generated by, CI/CD. CI/CD is not a great for reporting over time. Right? You wanna see, like, how many tests that we're running, pass/fail ratios, what teams are running, what tests, what, you know, what blah blah blah, these kind of things. And that's where you usually need a third party, reporting tool to help you because that's not something that CI/CD is built for. CI/CD is not built for testing. I can put it that way, which is kind of, it it it puts builds front and cluster, and testing is more a sub part of that.
Finally, giving control to QA. This is something we also see often. It's usually the DevOps team that manages GitHub actions or Jenkins pipelines. Right? So if the testing team says, "Hey, we need to go in and change some parameters for our, Playwright scripts." Okay. They'll say, "Okay. Submit a ticket in Jira, and we'll do it when we have time." Right?
They won't always give access to the CI/CD tool. This is maybe an enterprise or a large corporate product problem and not a small team problem, but it's a problem. So something also to be mindful of when you, that you have those processes, etcetera, figure out.
Okay. So how can you tackle those challenges? You can, many of them you can tackle by scripting, but, you know, and leveraging the features in your CI/CD tool. But, of course, the downside of that is that you'll have end up with more scripts, and it doesn't scale across multiple CI/CD tools. You can integrate point solutions, like Allure for test reporting, or you could use, like, a cloud, execution tool for running playwright tests more efficiently.
It'll require you to do more scripting in your GitHub actions or whatever. It also lead to a more fragmented infrastructure, it might which might be have maintenance or security concerns. Or you can also look at using a more purpose-built solution for test execution, which kind of provides a single pane of glass for all your tests, not just Playwright tests and decouples test execution from CI/CD.
This has a lot of benefits here as it'll be less scripting. It's kind of, it'll scale better with your efforts, but it might lack the depth that you might have in a point tool that is just focused on one specific thing.
Testkube Demo: Sharded Playwright with Merged Report
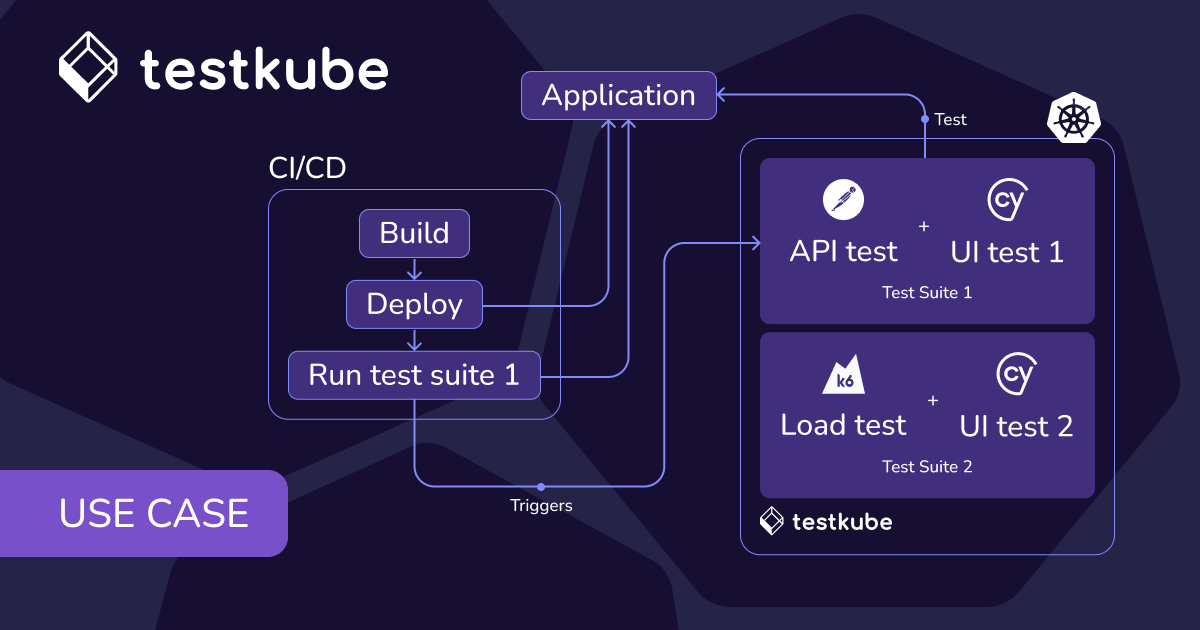
And, okay. I'm so short on time, but I do wanna talk about Testkube just quickly because that's where I'm from. So Testkube is one of the tools out there in the market that speaks to that last category in the space. So Testkube is a generic test orchestration execution platform. It integrates with any CI/CD solution and testing tool, including Playwright, of course. It provides that single pane of glass for all your testing activities. It's free. It's open source. It's on CNCF landscape. And, of course, there's a commercial offering because we don't we don't need to pay our bills and all that stuff. But, ultimately, it's a great way of, scaling your playwright test executions, and decoupling that from CI/CD.
In Testkube, we break down test execution into defining your tests. So we have a purpose-built workflow engine, triggering your tests. You can trigger them from your CI/CD or from events or from schedules or from CLI, from API, however you want to. You can scale test horizontally, vertically.
It has built in features for all the reporting and collecting, like, all the trace report we saw in the previous talk or any screenshots, movies, etcetera. It's kind of all built in, so there's much less scripting to do if you're using a tool like Testkube, for running your Playwright test. And then it has also reporting built in for all your tests. Right? So you don't need to, do that in a in a third party tool. Well, although Testkube is a third party tool, of course.
Okay. I don't know if I have time to do a demo. So, I am I'm just gonna show you just what that really quickly looks like. This is a Testkube dashboard.
I'm gonna show this was a a Playwright test that ran sharded across two workers.
What you can do here is you can look into the individual steps of that execution. So these were the different commands that were run by Playwright in my local environment.
And the nice thing is here is that it also then generates so this is a I'm gonna show the trace report that we talked about in the previous, session. So this is the trace report generated by Playwright.
Obviously, maybe not the best of testing scenarios, but you can see how cool it is. And you can also see once again, the nicety of having everything in one place. Right? And to set this up, you don't have to configure a bunch of long scripting.
It's something that's kind of very purpose built, into Testkube. And then you can in trigger these tests from GitHub Actions, GitLab, CircleCI, Jenkins, Azure DevOps, etcetera, etcetera. So we're not Testkube does not replace CI/CD for building and deploying. It just replaces it for testing.
And with that, I am done. And, well, thank you so much. And I see Rebecca jumping in here. I'm out of time in one minute.
Rebecca: Oh, you did great.
Ole: I did manage to stay within although the demo was a minute? Yeah. Okay. Well, thank you so much.
Reach out to to me if you're interested in Testkube or anything else related to Playwright. We have a Slack channel where you can go in and go to TestCube dot I and have a look. And thank you so much for listening.
Rebecca: Thank you so much. Alright, people. Thank you so much for joining. Thank you so much the for, to the panelists. And please, follow the Playwright user event on LinkedIn. So you we were gonna share the video as we mentioned earlier, and we're gonna keep you updated with everything else. Okay? So have a great rest of your day.
Ole: Thank you. Bye bye.

.webp)