


Table of Contents
Start your free trial.
Start your free trial.

Start your free trial.


Table of Contents
Executive Summary
At Testkube, we try to hold ourselves to the same expectations as our users. That means if we ask teams to use Testkube to orchestrate and scale their tests, we should be doing the same.
So, we do. We rely on Testkube to test Testkube.
In this blog, we'll share how our own engineering team uses the platform to continuously validate the product: where we are today, what's working well, and where we're still learning. You'll hear directly from our engineer, Tomasz Konieczny, about how we've built a system that helps us release with more confidence, while still leaving plenty of room for improvement. What we're showing here is just a part of the full process, a focused look at the most critical pieces.
Why We Use Testkube to Test Testkube
"We use Testkube for almost everything — it's our main tool. We approach it the same way a user would, just maybe at a larger scale." – Tomasz Konieczny, Engineer at Testkube
We believe that by using the product ourselves (in realistic, often high-volume environments) we'll build something more reliable and empathetic. We run a variety of test types across workflows, tools, and infrastructure configurations. Many of the workflows we run mirror what we see customers doing, and sometimes we learn from edge cases before they even happen in the field.
This approach has already paid dividends. Issues that might have slipped through traditional testing get caught because we're experiencing the same pain points our users would face. When something breaks in our own workflows, we feel it immediately, which creates a powerful feedback loop for improvement.
What We Test Internally
Installation & Upgrade Validation
We run tests to make sure both the agent and control plane components of Testkube can be installed consistently across different Kubernetes versions and environments. These tests are re-run frequently and before every release, giving us confidence that deployments will work smoothly for our users.
Tool and Feature Coverage - TestWorkflows
TestWorkflows are one of the core and most critical features of Testkube. Ensuring their correct and consistent execution is essential to the platform's stability and reliability.
Therefore, we've built — and continuously expand — a large set of test workflows (currently over 150) covering a variety of testing tools, configurations, and workflow features. This extensive coverage means we can catch compatibility issues and regressions across the entire ecosystem of tools our users depend on.
The list includes 20 testing tools: Playwright, Cypress, Postman, k6, JMeter, Gradle, Maven, and more. These workflows cover a range of common usage scenarios, often across multiple tool versions and popular configurations, including distributed execution variants.
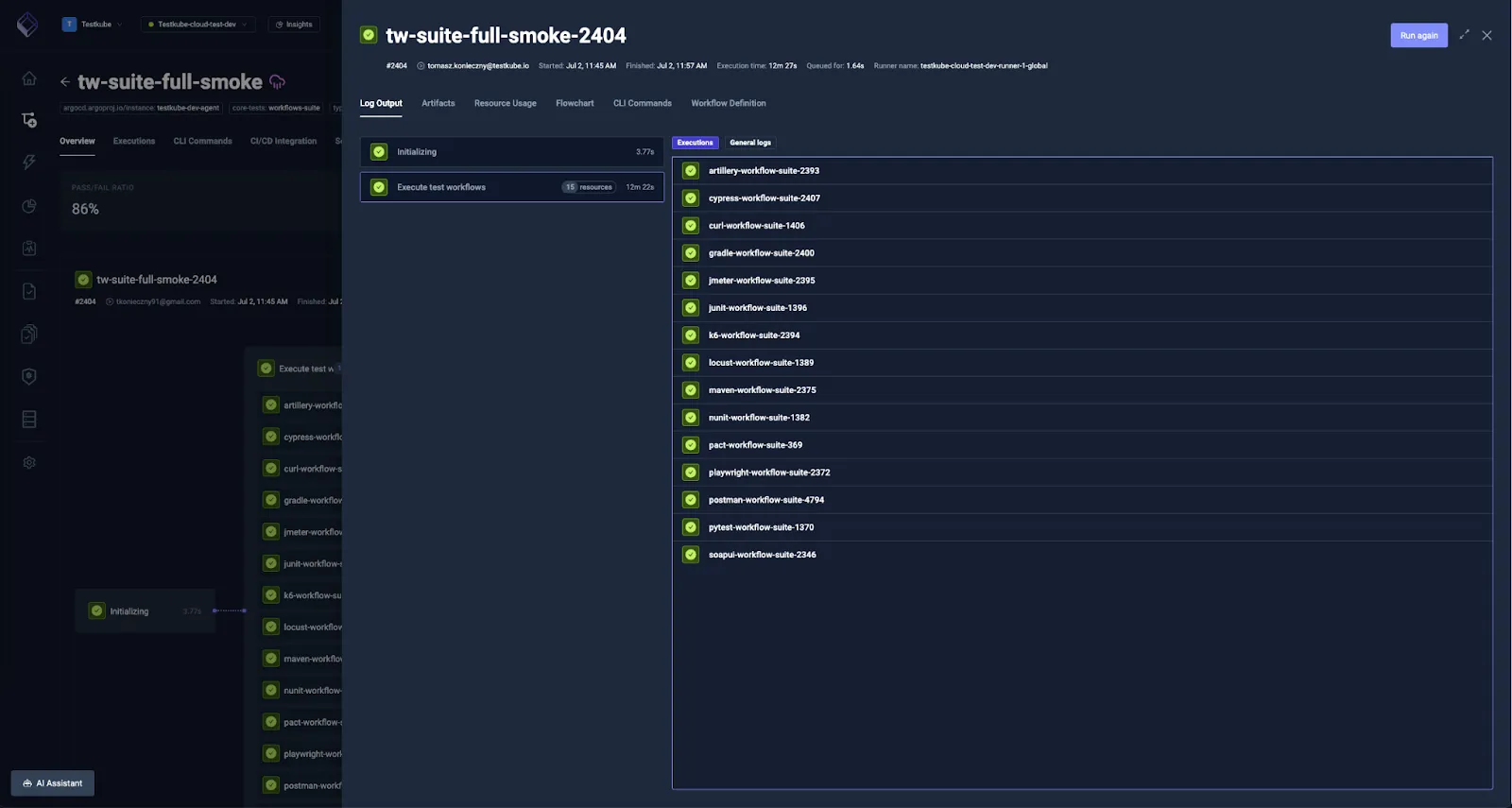
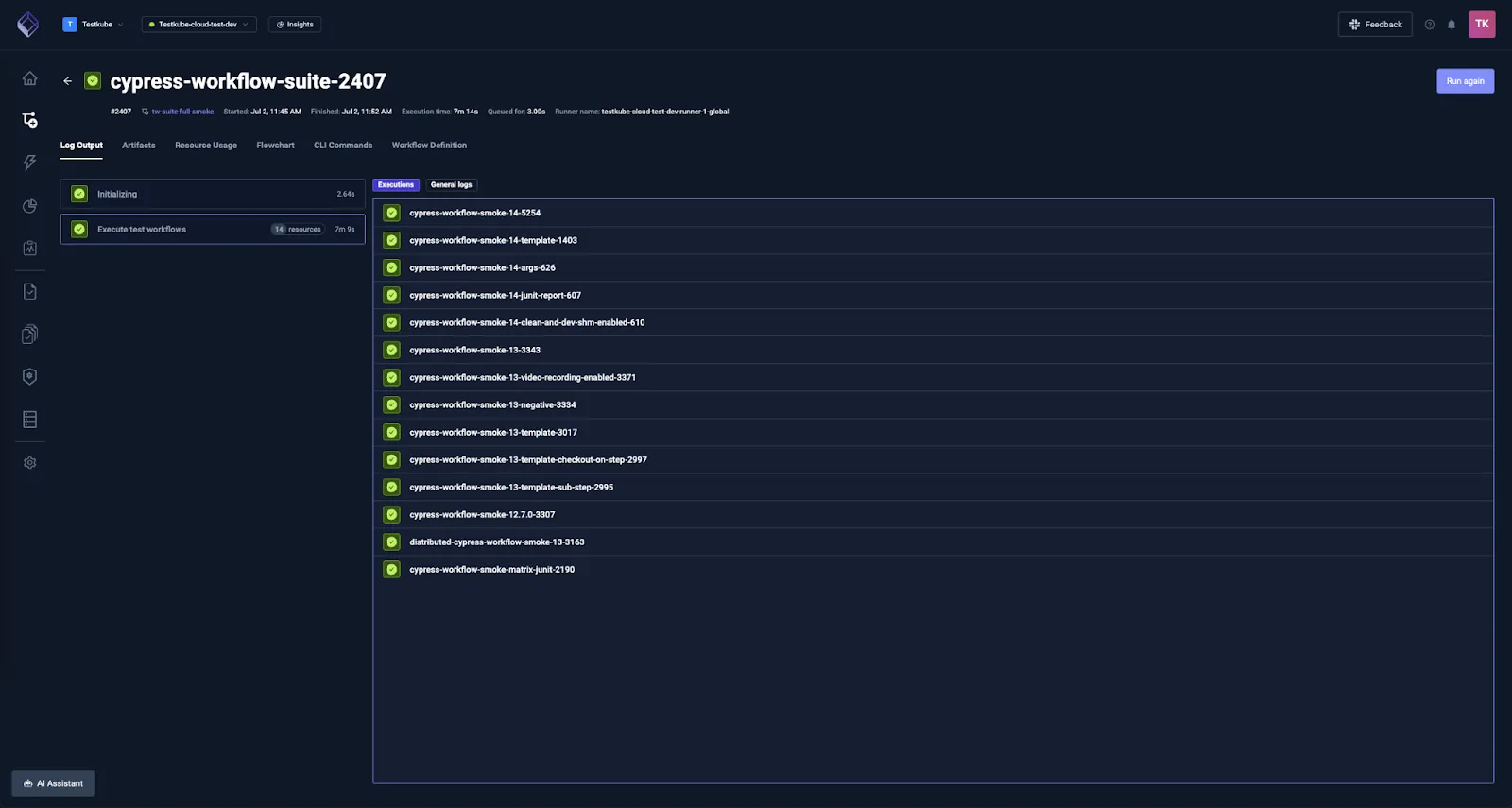
They also validate different Testkube features and configuration options, starting from the most basic like test content, execution steps, and commands, through templates, to more advanced functionalities such as Testkube expressions. Some of them even cover highly custom TestWorkflow cases, like running Android tests (Espresso) in a KVM-based emulator or using ephemeral DinD+Kind clusters for Testkube installation tests.
The workflows serve a dual purpose: they are essential for ensuring Testkube works correctly and reliably, and they also act as practical examples for users. While the coverage is not yet exhaustive, it's a growing library aligned with real-world usage patterns.
End-to-End Testing
Moving beyond individual components, we use Playwright to validate core user flows through the dashboard. These tests focus on the experiences that matter most to our users: creating and interacting with workflows, configuring triggers and webhooks, and managing environments.
"The primary goal of these tests is not exhaustive bug detection, but verification that the most important user flows work correctly end-to-end. However, tests are heavily data-driven, which allows easy coverage of multiple variants of each flow. A full set of API helpers is used not only for handling preconditions and result verification, but also as reusable building blocks for other types of tests." – Tomasz
These E2E tests are intentionally limited to the most important user flows, prioritizing reliability of core functionality over exhaustive bug detection or edge case coverage. They are triggered on every pull request to catch regressions early and ensure that critical paths remain reliable and functional.
Expected Failures: Testing What Breaks
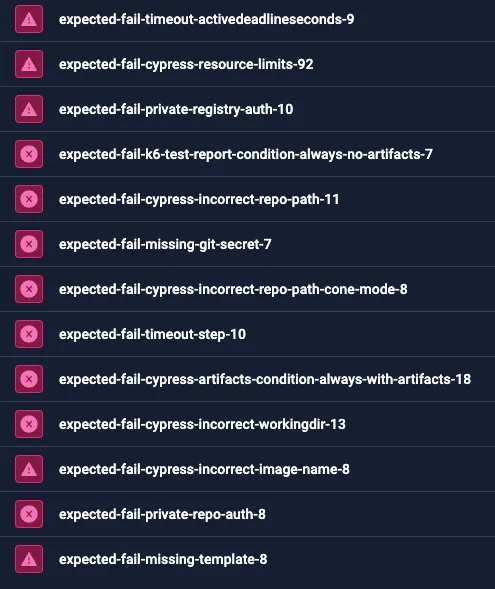
Alongside positive test cases, we maintain a dedicated test suite focused on edge cases and controlled failure scenarios. This might seem counterintuitive, but it's crucial. Real-world testing environments are messy and things go wrong. We want to ensure that when they do, users get clear feedback and the system remains stable.
"Failures are part of real-world testing. We want to make sure that when something goes wrong, users get useful feedback — and the system stays stable and predictable." – Tomasz
These tests verify that errors are correctly reported and handled without crashes, hangs, or undefined behavior, whether caused by user misconfiguration, system limits, or unexpected runtime conditions. The suite covers a wide range of edge-cases and failure types, including out-of-memory terminations, step and workflow timeouts, invalid or missing configuration (like secrets, variables, volume mounts), broken or malformed test reports (invalid JUnit/XML), cluster-level resource exhaustion, and log-heavy workflows that produce large outputs.
We specifically test the correctness of behaviors such as timeout enforcement, resource limit handling, and failure propagation, ensuring these mechanisms respond predictably under edge conditions.
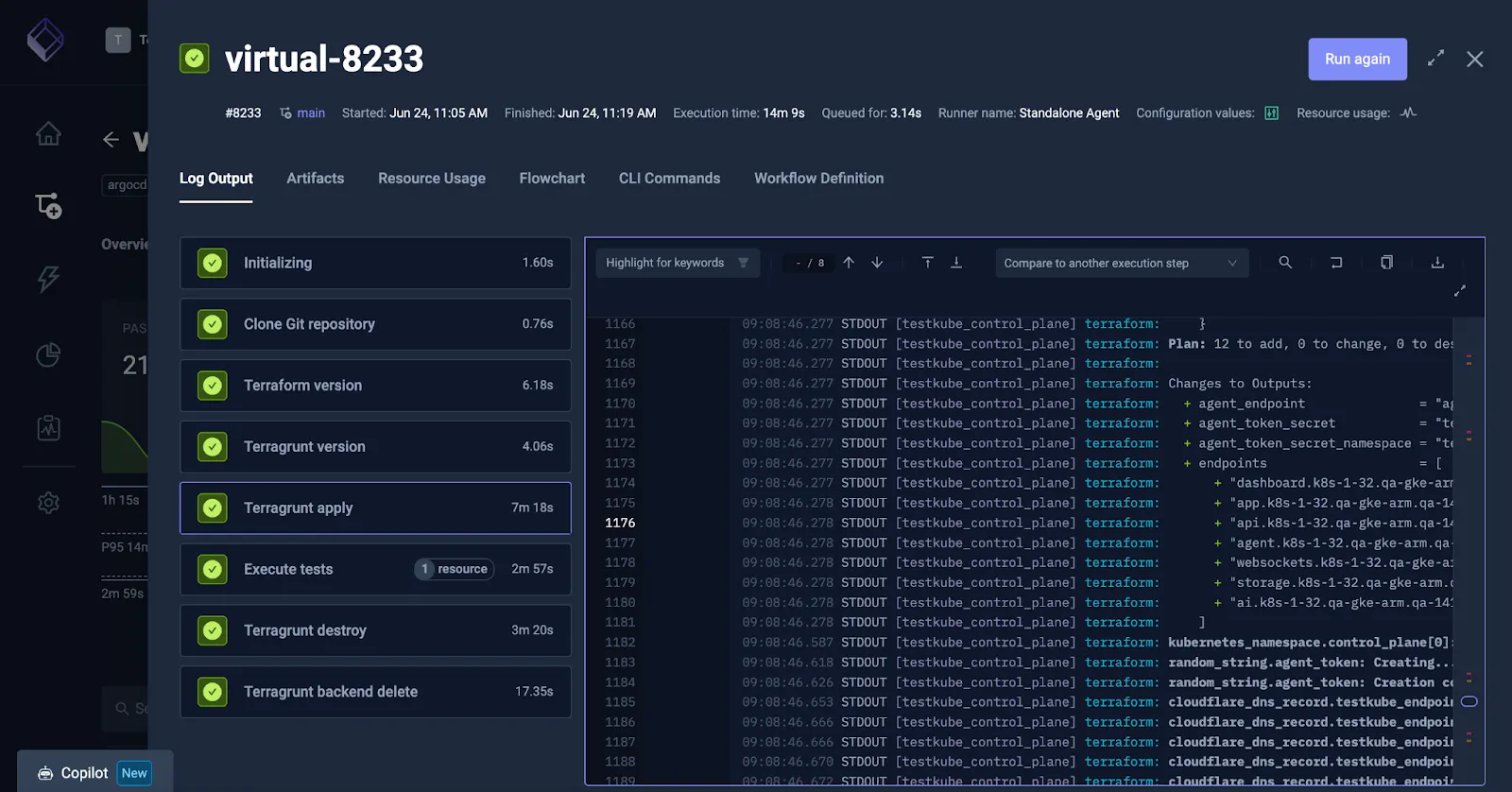
Validating Across Cloud and Kubernetes Environments
We try to mirror customer environments as much as possible. Our customers deploy in different cloud environments and configure both Testkube and Kubernetes in many different ways. Our application needs to be compatible with all those configurations and reliably install across diverse setups without flaky behavior.
Recently, Testkube developed an internal framework which can be utilized to define, provision, and validate releases against various configurations of Testkube, Kubernetes, and cloud infrastructure. This systematic approach helps us catch environment-specific issues before they impact users.
How It Works:
- Terraform and Terragrunt provision the clusters and infra
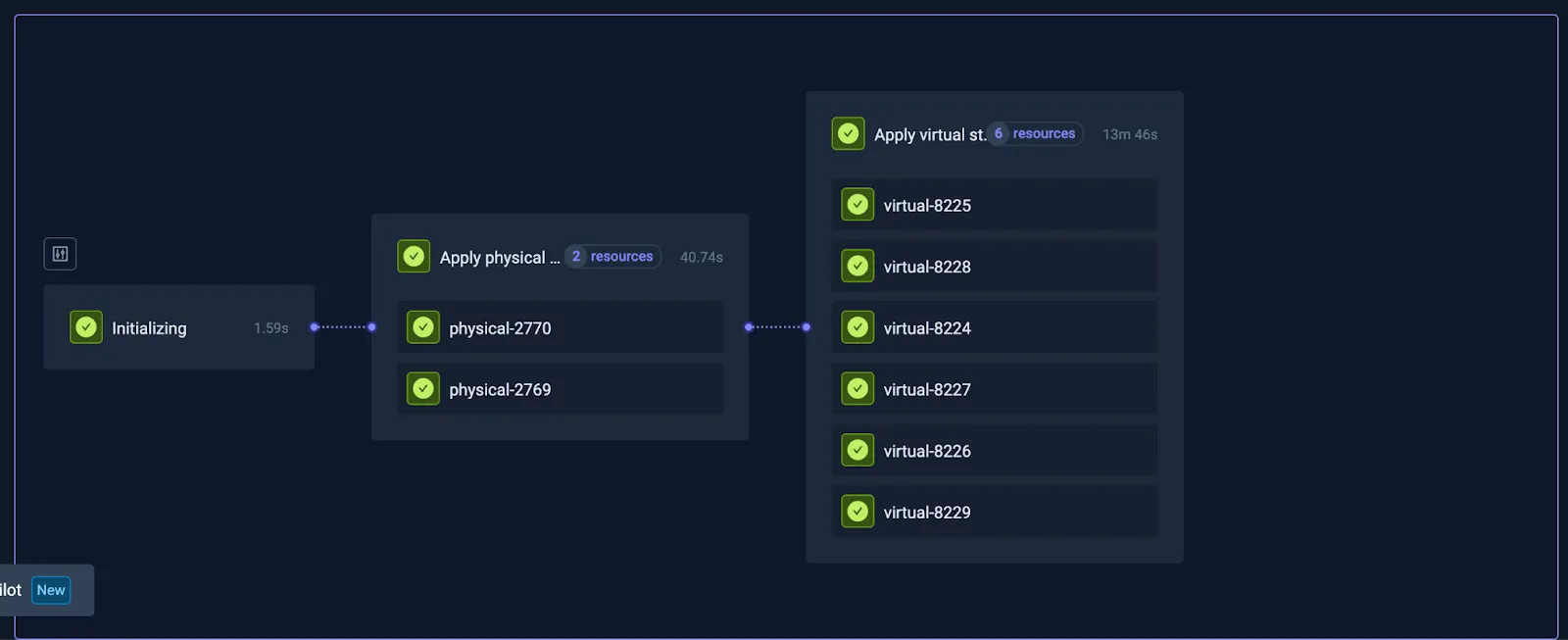
- We test on both AMD64 and ARM64 architectures
- We use vCluster to spin up virtual clusters for faster and isolated tests
- We support multiple Kubernetes versions (currently 1.30–1.32)
- Tests are triggered every 3 hours, and for every release candidate
The advantage we get with the virtual layer is that the instances are isolated and we can quickly spin them up and tear them down.
This gives us a broader view of installation stability and configuration behavior, though we know there's still more to cover.
Looking ahead, there's room for expansion in this area. The possibilities are extensive given the many ways to configure Testkube and the Kubernetes clusters it operates in. Future improvements include testing with private CA certificates, different image registries, and direct cloud provider integrations.
This scheduling strategy ensures we get rapid feedback on the most critical functionality while still maintaining comprehensive coverage when we need it.
How We Schedule Automated Tests
Developer Experience and Feedback
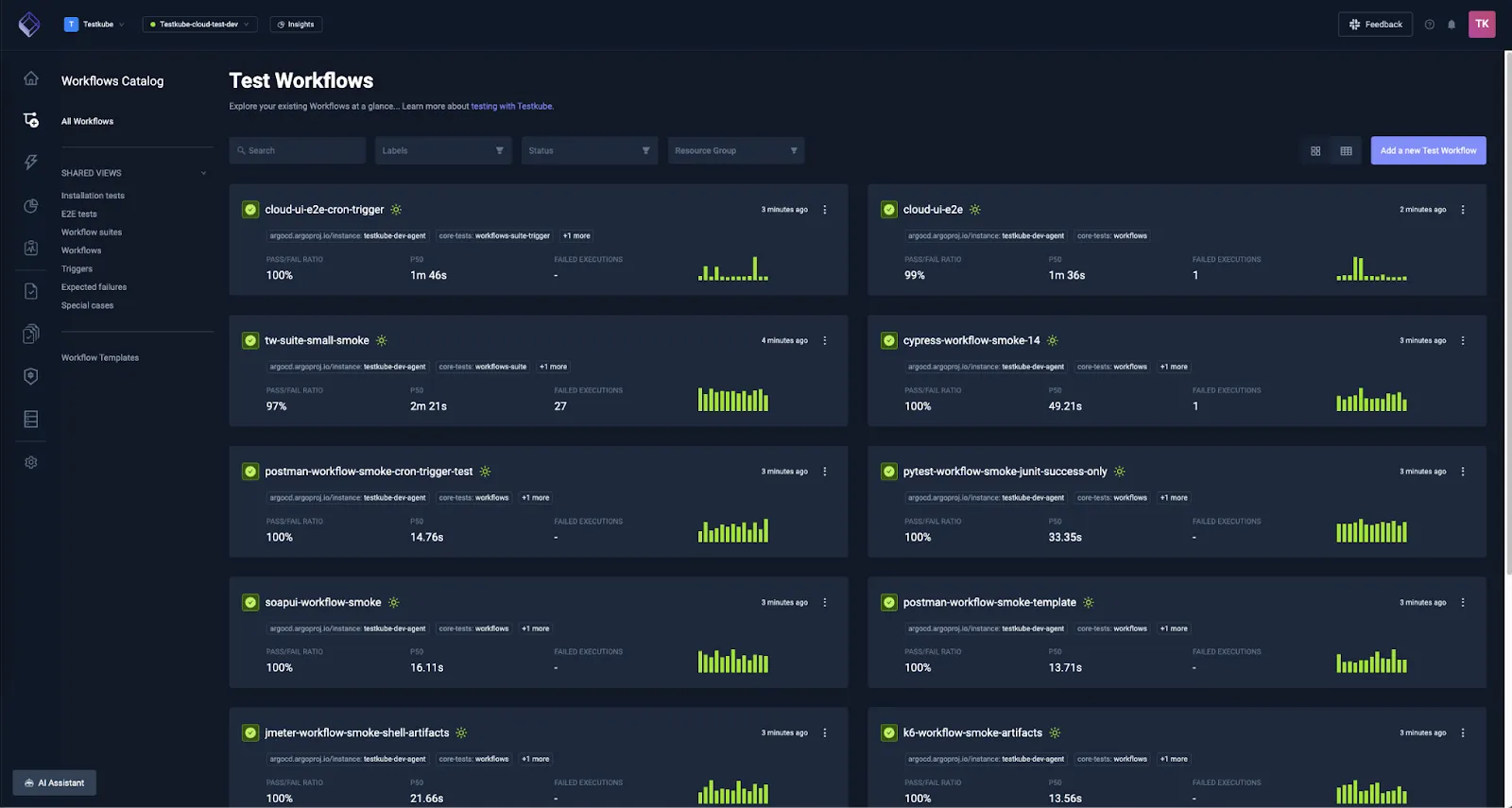
For our needs we use Testkube Control Plane and Dashboard: this is what makes everything visible and manageable. We use the GitOps approach, have everything versioned in the repository (TestWorkflows, "suites", triggers, webhooks) and synced automatically.
Tests are wired into our daily workflows: GitHub Actions integration triggers tests and posts feedback on PRs, while Slack integrations alert us when something breaks. This means issues surface quickly and in context, rather than being discovered days later.
"Each time someone works on a feature, we try to ensure there's a way to trigger the relevant tests — quickly and with context. We've made a lot of progress filling in long-standing gaps, especially in the last few months. But there's still plenty of work ahead. Quality isn't a milestone, it's a continuous process." – Tomasz
Why We're Sharing This - And What It Means for You
We don't think our process is the gold standard, but we do think it's worth sharing. We've learned a lot by treating ourselves as users of the product. It's helped us improve stability, fix bugs before they reach production, and build empathy for the teams relying on us.
"We use Testkube the same way our users do. That helps us understand what's working — and what still needs work." – Tomasz
More importantly, this approach benefits you as a user. When we experience the same challenges you face (slow feedback loops, flaky tests, complex configurations), we're motivated to solve them not just in theory, but in practice. Every improvement we make to our own testing experience becomes an improvement we offer to you.
If you're trying to build similar processes in your organization, or if you just want to hear how other teams are approaching testing at scale, we're happy to share, collaborate, and learn together. After all, just like you, we're all trying to ship better software with more confidence.
About Testkube
Testkube is the open testing platform for AI-driven engineering teams. It runs tests directly in your Kubernetes clusters, works with any CI/CD system, and supports every testing tool your team uses. By removing CI/CD bottlenecks, Testkube helps teams ship faster with confidence.
Get Started with a trial to see Testkube in action.
.png)

