

Table of Contents
Start your free trial.
Start your free trial.

Start your free trial.



Table of Contents
Executive Summary
“What’s our test pass rate in this sprint across all the services?” It’s a straightforward question, and someone surely has the answer.
But here’s what actually happens - QA checks their dashboard and says 88% pass rate. It doesn’t stop here. The QA team runs their tests in Gitlab, platform team in Jenkins and the frontend team uses GitHub actions while the API team has their own CircleCI setup. Each system reports its metrics in a different format.
A few hours and spreadsheets later, you have an approximate answer because the data formats don’t align. Some call it “smoke test”, some call it “sanity tests”, while the retention policy is set up differently across all systems, so some tools have the stats, while some don’t.
That is pipeline sprawl in action. When teams moved from monoliths to microservices, each team got autonomy to choose their CI/CD tools and optimize their workflows. Result? Test execution was fragmented across dozens of disconnected systems, making feedback impossible.
The way forward is to understand that continuous feedback is the need of the hour, and it requires a centralized orchestration - not additional dashboards or faster pipelines.
In this post we’ll look at what continuous feedback actually looks like and how Testkube helps implement continuous feedback.
What Continuous Feedback Actually Looks Like
To understand what continuous feedback is and how pipeline sprawl breaks it, we need to focus on what “working” is and what should be possible when continuous feedback actually works.
For Developers
Developers need fast, actionable feedback that keeps them in flow. Continuous feedback means testing happens automatically and test results appear where they're already working - no tool switching, no hunting through dashboards.
What this looks like in practice:
For QA Engineers and Testers
QA Engineers and testers need control over test execution across the organization without waiting for the DevOps team to update the pipeline configuration. Testers can write, verify, and deploy tests independently, then track results regardless of how or where those tests were triggered.
What this looks like in practice:
For QA Managers
QA Managers essentially need answers to quality questions at one place without sifting through multiple reports and dashboards across system. They want to move from a firefighting and reactive strategy to proactive mode which will be enabled via unified visibility.
What this looks like in practice:
For Engineering Leaders
Continuous feedback provides visibility to engineering leaders and enables them to take strategic decisions without affecting team’s autonomy. Quality is now measured, and governance is baked in without slowing down teams.
What this looks like in practice:
This was a glimpse of continuous feedback in action when architecture supports it. Let’s now understand why pipeline sprawl makes it impossible for most organizations.

Why Pipeline Sprawl Killed Your Feedback Loops
The continuous feedback examples we looked at in the previous sections aren’t theoretical and can be easily achieved. But most organizations aren’t able to get this right. The answer lies in progressive failure where each team’s local optimizations create organizational-level dysfunction. Let’s trace how it happens.
Stage 1: Local Optimization
It all starts with the teams choosing their own set of CI/CD tools based on their requirements. The backend team prefers Jenkins for complex build pipelines, the front-end team wants GitHub actions for better integration with their workflows, and the platform teams choose CircleCI for better security scanning configuration.
It all looks good - it passes all the individual team requirements, allows teams to ship faster, and provides local continuous feedback.
From inside any team, this looks optimal.
Stage 2: Fragmentation Emerges
3 months down the line, you now have 15 teams running tests across 8 different CI/CD platforms. Each team has its own execution logic, reporting format, artifact storage, and retention policy. Test results live in incompatible systems, each requiring a different query language.
When the engineering leadership asks questions like “What’s our org-wide test pass rate?” or “Are we running security scans before every production deployment?”, it is then that teams realise the answer to these questions is not straightforward.
Each question requires checking multiple systems, manually correlating data, and hoping the vocabulary is consistent across teams. A QA manager will spend a few hours just collating results from different dashboards, loading them into Excel, and then forming an approximate answer.
Stage 3: Feedback Loops Break
The fragmentation is now actively handled by the platform team in Jenkins, and the frontnd team uses GitHub actions,events, and continuous feedback capabilities that we described earlier. And there are four specific atterns that emerge:
Visibility Crisis
With so many disparate systems, answering questions spanning across service becomes impossible. Each team knows their local pass rate, but nobody knows what the organization-wide number is. The data exists but on incompatible systems, different calculation methods and retention policies.
Even to answer a question like “Is component X ready for production release?” requires manually checking the status across multiple pipelines and environments.
Delayed Detection Pattern
Let’s look at a shared authentication library that all teams use. It gets updated and within a few hours, all the services deploy the new version. Four of them break in production.
Root cause analysis reveals that different test suites caught authentication failures - but in GitLab, Jenkins and a standalone environment. The teams that deployed successfully never saw this failure because they checked only their pipeline logs, which showed green.
According to Cloud Security Alliance analysis, this pattern - where security controls aren't consistently implemented across pipelines - causes 50-80% of cloud vulnerabilities. The controls run somewhere; they just don't run everywhere. And without unified orchestration, the gaps are invisible until production breaks.
Context Switching Tax
With pipeline sprawl, even a single test failure triggers a tool-switching cascade. The developer gets a notification of a failed test. They open GitHub actions and sees the test failed. Clicks on the test status link and sees that unite tests passed, integration tests also passed. Then opens Jenkins and finds no clue. Then opens GitLab and finds that it failed because of a failure in another system.
All the while, the developer was only searching for the failure. No debugging or fixing it. Consider the number of developers on the team and the number of failures every day; these compound into huge productivity losses.
Control Paradox
In most situations, QA teams become responsible for quality outcomes but lose control over test execution. Tests are not part of a DevOps-managed pipeline across multiple teams and systems.
Want to update your testing process? File a ticket for each pipeline and follow up until it is fixed. QA has the accountability but not the authority.
Stage 4: Failed Solutions
At this point, organizations have realised that they have a problem. More often than not, they try either or all of the following solutions:
- Standardize on one CI/CD tool: Sounds logical. But in practice, it requires ripping out working systems, retraining teams, migrating complex workflows, and still doesn't solve the core issue - test orchestration needs differ from CI/CD orchestration needs.
- Build better dashboards: Aggregates data from multiple sources into prettier graphs. The data remains scattered, the execution remains fragmented, the quality gates remain inconsistent. In a way, you've visualized the problem, not fixed it.
- Automate more: Each team adds more automation in their preferred tool. More fragmented automation produces more fragmented results. Local optimization, organizational dysfunction.
The core insight here is that you cannot have continuous feedback loops when the test execution is fragmented across independent systems. This isn’t a tooling problem, but an architectural problem. Test orchestration needs architectural separation from CI/CD orchestration.
The Architectural Answer: Centralized Testing Orchestration
We have established the problem that fragmented test execution breaks continuous feedback at an organizational scale. The solution to this problem is architectural - you need to rethink where testing lives in your architecture. Not which CI/CD tool to standardize, but what layer sits above all of them.
Before we get into the architecture, it’s important to understand what “centralized testing orchestration” means (and doesn’t.)
Drawing parallel from Kubernetes for container: one control plane, workloads run anywhere. Teams choose how to build and deploy their apps; Kubernetes provides the orchestration layer that makes it manageable at scale. This same pattern pplies to testing as well.
The Decoupled Architecture
Separating Concerns
This architectural shift starts with recognizing that test orchestration and CI/CD orchestration are distinct concerns with distinct requirements.
- CI/CD tools are great at building code, managing, orchestrating release workflows, and coordinating between development and operations.
- Test orchestration means executing tests consistently across environments, aggregating results regardless of trigger source, enforcing quality gates, and providing observability.
Trying to use CI/CD tools to handle both creates fragmentation we discussed earlier. And the answer we now know is architectural separation. But how do we do that?
Tests as Infrastructure
In this pattern, tests run as Kubernetes-native workloads - jobs and pods - not as tasks that are tied to a CI/CD pipeline. This provides critical benefits like:
- Consistent execution behaviour: Irrespective of whether the test is triggered by a GitHub action or an Argo deployment, it runs in the same infrastructure with the same configuration.
- Elastic scaling based on test workload: Need to run 1000 E2E tests? Kubernetes can distribute them across available nodes, parallelize execution and complete the execution in minutes.
- Resource isolation and control: Each test execution runs in it’s own pod with dedicated resources, preventing any interference between tests.
Event-Driven Triggers
One of the major advantages of a decoupled architecture is that the tests can be triggered from any source and not just CI/CD pipelines:
This flexibility enables patterns like continuous validation throughout the development lifecycle - tests run when they're needed, where they're needed, triggered by the events that matter and not locked to a specific pipeline stage.
Control Plane Pattern: Unified Orchestration
A centralized control plane ensures the execution of tests is distributed, while the coordination and orchestration are centralized. It ensures that tests execute across development, staging, and production clusters seamlessly.
- Tests execute locally within each environment, preventing network hops to external clouds
- Results are aggregated to the central control plane for unified visibility - all test results, logs, and artifacts flow to the centralized storage regardless of the trigger source.
- Quality gates are defined once and enforced everywhere by the orchestration layer - no need for manual configuration in 10 different pipeline YAMLs
What This Architecture Enables
Because continuous feedback translates different for different users, here’s what each persona will experience when this architecture is implemented:
The continuous feedback capabilities described earlier become achievable now: developers get fast feedback regardless of their CI/CD tool, QA engineers and testers deploy tests independently, QA managers see organization-wide metrics, and engineering leaders enforce consistent standards.
How Testkube Implements Centralized Orchestration
We’ve established an architectural pattern to address the fragmentation problem and address the continuous feedback concern. Let us understand how Testkube translates each of the architectural principles into concrete implementation.
Kubernetes-Native Foundation
Testkube runs entirely within your Kubernetes infrastructure, not as an external SaaS dependency. The control plane deploys in your clusters, tests execute as native Kubernetes Jobs and Pods, and all data stays within your infrastructure. You can connect your development, staging and production clusters to a single control plane.
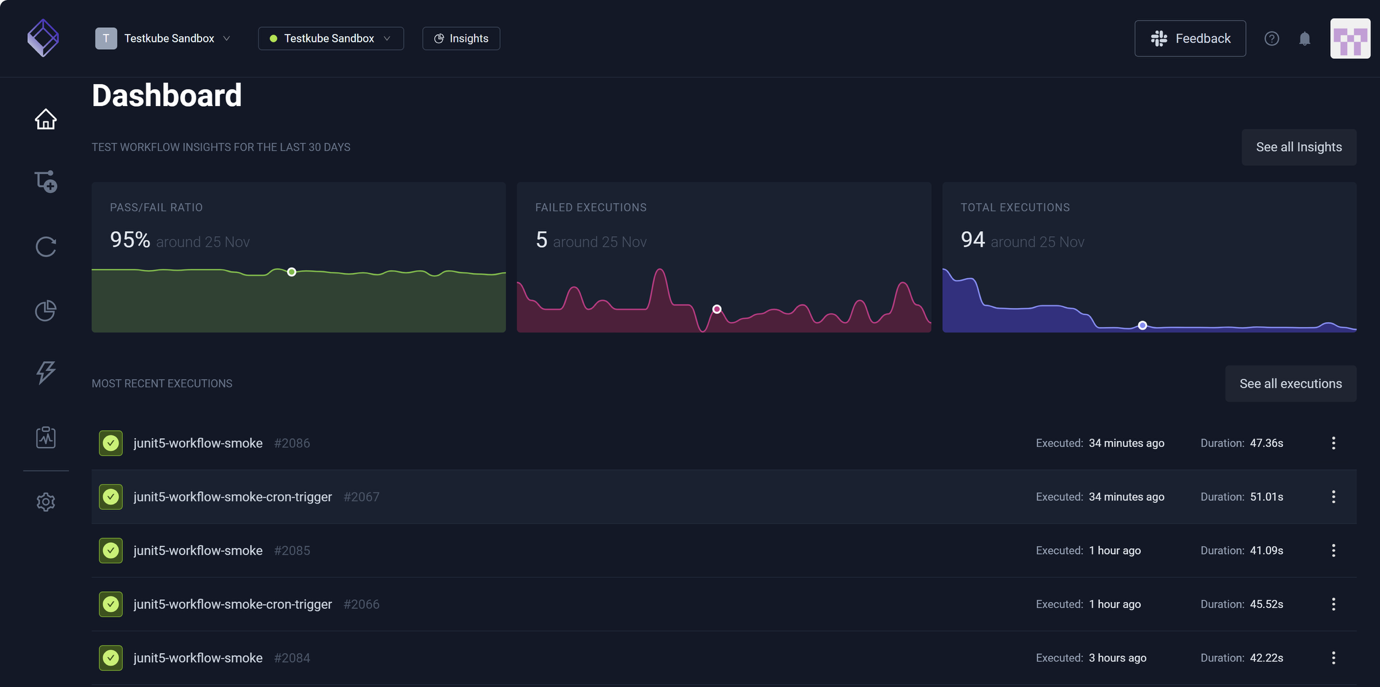
Further, the tests run as Kubernetes workloads with full fine-grained resource control. You can define the CPU and memory requirements for each test individually. Kubernetes handles the scheduling, isolation and cleanup automatically.
CI/CD-Agnostic Integration
Testkube implements the orchestration layer pattern by integrating with existing CI/CD tools without replacing them. Teams keep Jenkins, GitHub Actions, GitLab CI, CircleCI, Argo, or Flux - testing becomes CI/CD-agnostic.
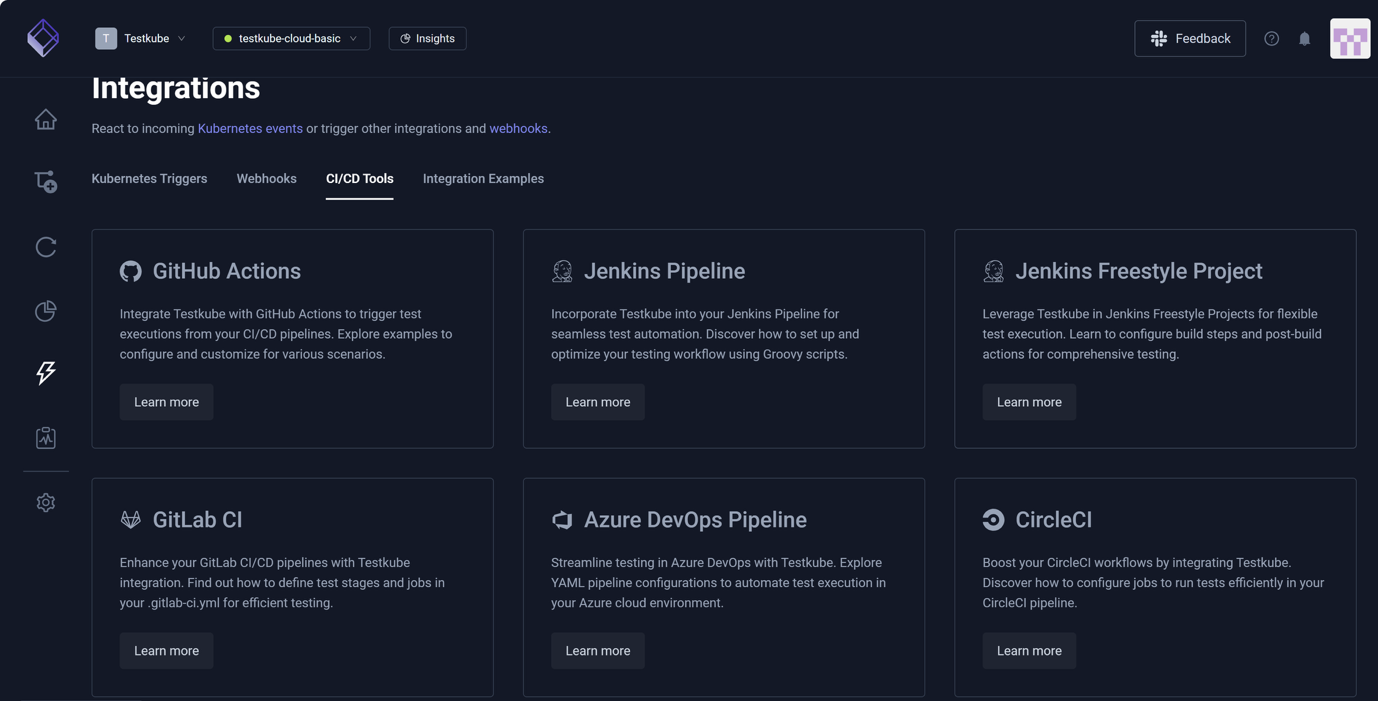
CI/CD pipelines trigger test execution via Testkube API or CLI. Tests are executed in the Kubernetes infrastructure. Results flow back to the CI/CD tool for pipeline decisions. This way, each team continues using their preferred tool for their workflow while each team triggers a test via Testkube.
Unified Observability and Results
Testkube becomes the single source of truth. All test results, logs, and artifacts aggregate centrally regardless of trigger source or execution environment.
The centralized dashboard shows test execution and results across teams, environments and trigger sources. AI test insights providing advanced analytics to identify patterns that are invisible in fragmented systems.
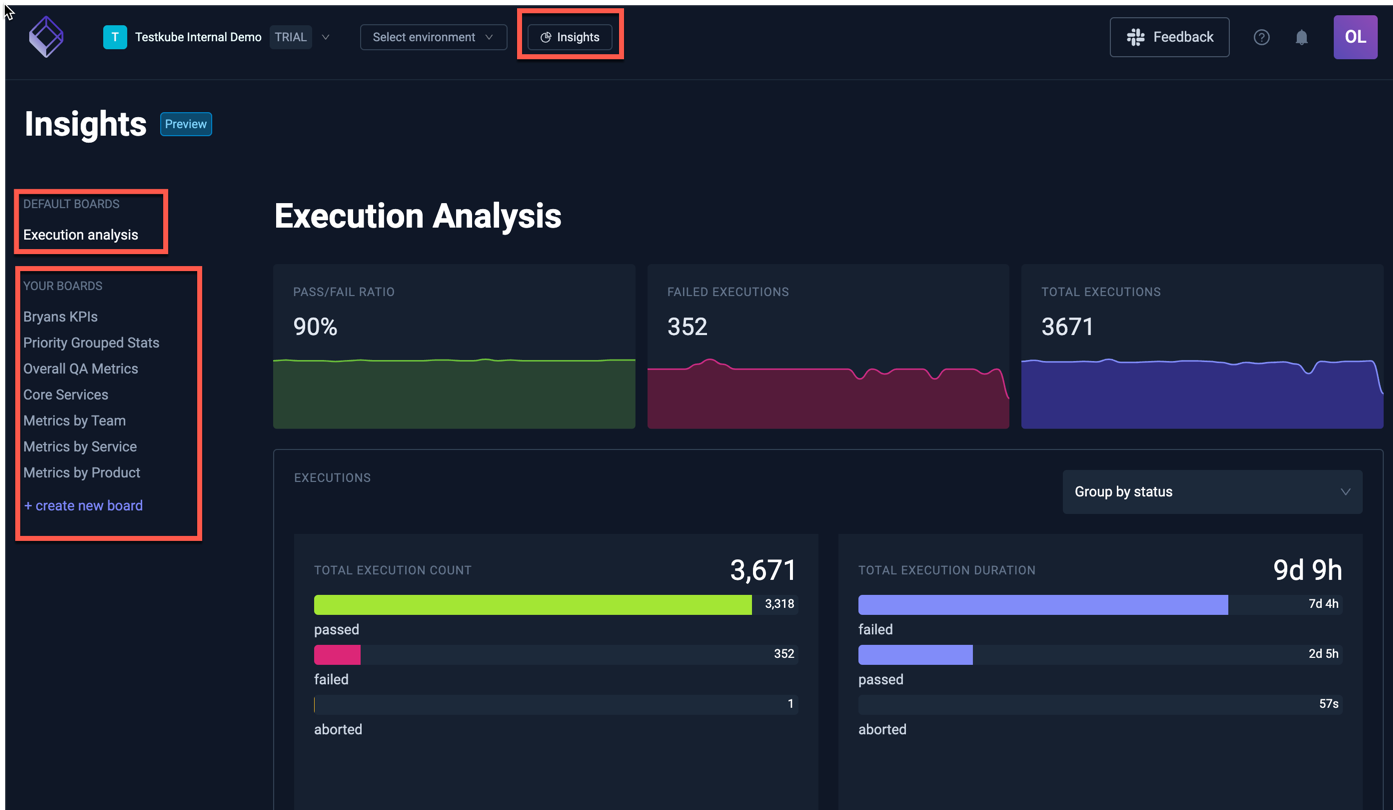
With AI powered troubleshooting, developers no more need to manually correlate logs across systems. AI analyses the logs and suggests the root cause with relevant log excerpts and suggested fixes.
Multi-Framework Support
Testkube orchestrates any testing tool out of the box. Frontend team using Playwright for E2E testing, Services team using Postman for API Testing, performance team using k6 for load-testing, Platform team using curl for infrastructure validation, security team using custom scripts for vulnerability scanning - all of them can be orchestrated through Testkube with unified visibility.
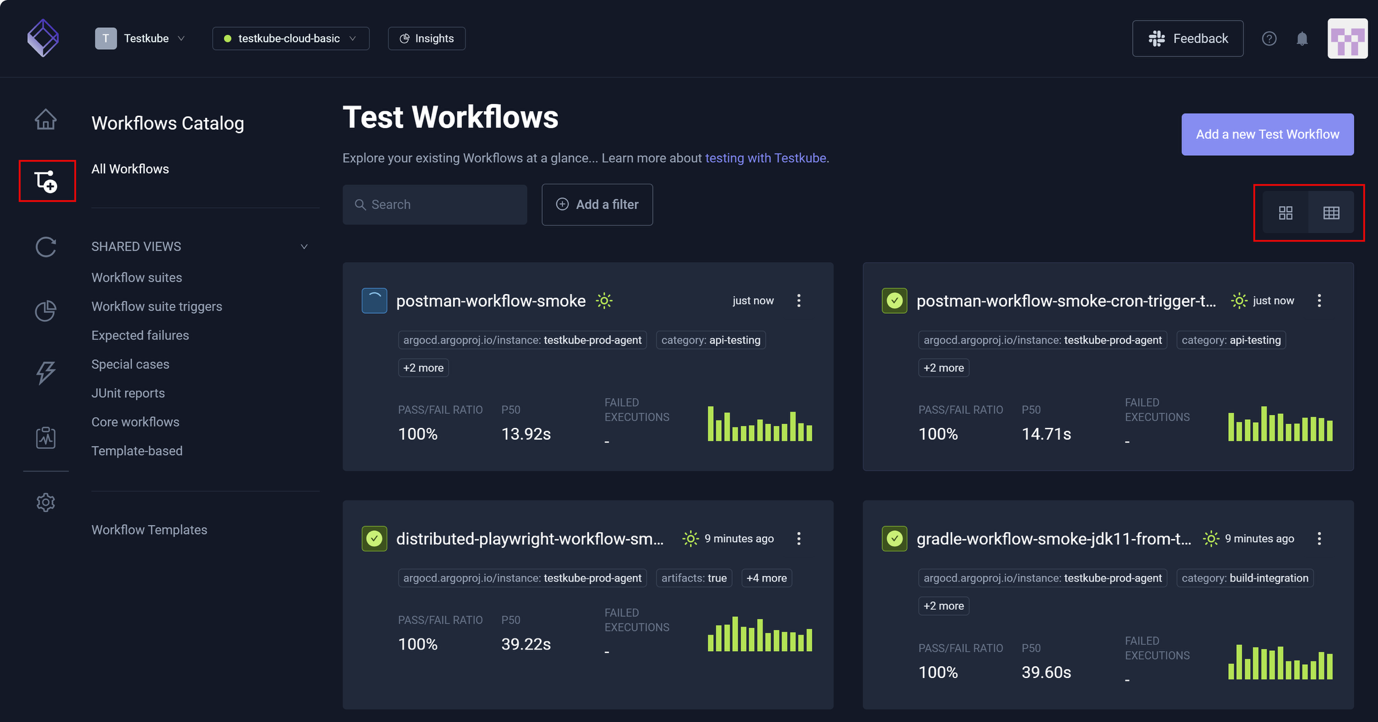
The Testkube Control Plane and Workflow engine abstracts framework differences while preserving the unique capabilities of every tool while providing unified workload definitions with consistent trigger mechanisms and aggregated results.
Scalable Execution in Your Infrastructure
Testkube leverages Kubernetes for flexible and scalable test execution without using an external test clouds with expensive pricing.
It allows you to distribute tests across nodes with zero manual inputs. Run 1000 tests across 50 pods in parallel and get results faster. Kubernetes takes care of all the scheduling and resource allocations.
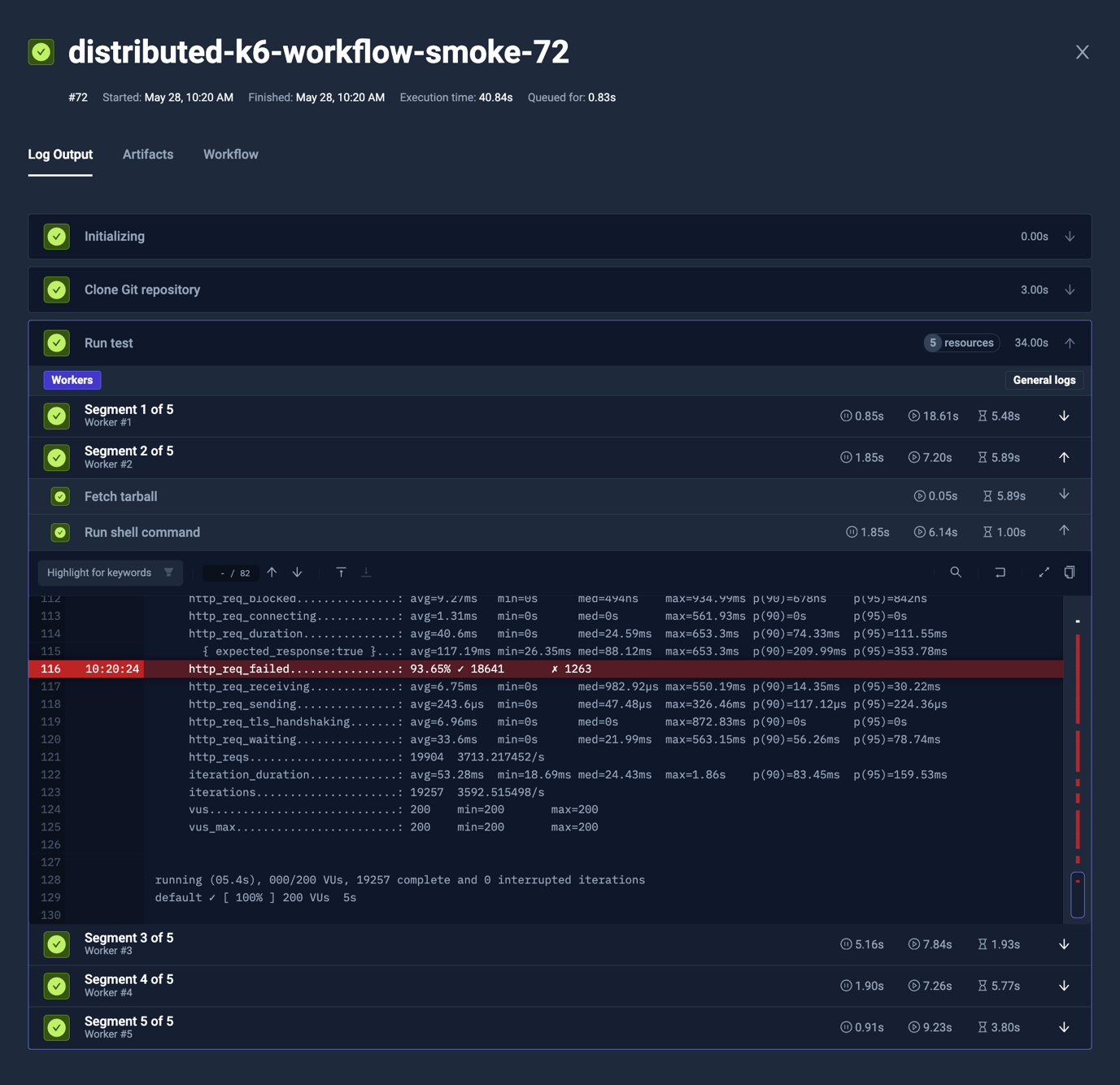
You can shard and distribute your large tests suites automatically across workers. Split your 500 E2E tests shards across 25 pods, each running 20 tests, and all completing simultaneously.
You use the same Kubernetes clusters running your applications to also run your tests. No separate test infrastructure to maintain. No data egress costs sending test artifacts to external systems
Conclusion: When does this approach make sense?
Having looked at the architecture patterns needed to enable continuous feedback, how do you decide when this approach makes sense to you?
Ask yourself these two questions:
- Can your leadership answer basic quality questions like "What's our test pass rate across all services?" If the answer requires teams to check multiple systems and correlate logs, you need centralized orchestration.
- Do teams have both autonomy and governance? Teams should choose their CI/CD tools and iterate on workflows independently. The organization should enforce quality gates consistently and audit compliance easily.
If the answer to both the questions is no, you need centralized orchestration. You’re probably managing many fragmented pipelines where QA doesn’t have control, engineers waste time correlating logs and context-switching, and compliance requires manual aggregation.
Pipeline sprawl doesn't require ripping out CI/CD tools. It requires an orchestration layer above them. Schedule a demo to learn more about how Testkube implements centralized test orchestration.
About Testkube
Testkube is the open testing platform for AI-driven engineering teams. It runs tests directly in your Kubernetes clusters, works with any CI/CD system, and supports every testing tool your team uses. By removing CI/CD bottlenecks, Testkube helps teams ship faster with confidence.
Get Started with a trial to see Testkube in action.


