

Table of Contents
Start your free trial.
Start your free trial.

Start your free trial.



Table of Contents
Executive Summary
Your developers are using AI coding assistants like GitHub Copilot, Cursor, or Claude, and shipping features faster than ever. More pull requests, new microservices in minutes instead of hours - the entire engineering team is more productive than ever. Industry research reports show that 63% organizations now ship code faster since adopting AI coding assistants.
But there’s a problem hidden underneath the success metrics and velocity dashboards. 72% of the same organizations that already suffered at least 1 production incident directly caused by AI-generated code.
This isn’t about AI generating bad code, but it’s about the fundamental mismatch between how it generates code vs how we validate it. Teams reporting upto 2x velocity are staring at the growing number of PRs, strained CI/CD pipelines, and the long code review process.
Teams are realizing that code velocity isn’t the same as business velocity.
This is where most discussions about AI coding assistants get it wrong. The solution isn't just running more tests or adding more CI/CD runners. It's evolving your entire approach to testing to match AI's pace.
For engineering leaders, this requires a fundamental shift in how testing infrastructure is architected, evolving from a pipeline-centric testing approach to testing being performed continuously as independent, orchestrated workflows that match the pace of GenAI-driven organisations and teams.
Bottleneck Transfer: Where AI Velocity Gets Lost
We all know that AI coding assistants are changing the economics of software development. Tasks that were once complex - remembering syntax, scaffolding boilerplate code - now complete in minutes or even seconds.
While the velocity has certainly improved, it creates an illusion that the teams are “more productive”. Spike in commit velocity, PRs look impressive, but these measure activity, not outcomes. The code still needs to integrate with your existing systems, handle your specific business logic and edge cases, and work reliably under production conditions.
AI has not eliminated the validation work, as someone still needs to validate it; the bottleneck is just transferred.
Context Engineering
The first bottleneck appears in context engineering. For an AI coding assistant to generate code that actually follows your patterns, adheres to your business logic, and integrates cleanly with your existing services, someone needs to provide this context. This is often in the form of prompt, structured documents or example codes. And that’s where this context work becomes critical. It’s a new skill that sits between requirements and code generation, and many developers lack it.
Code Review
Next comes code review. AI generates code at a rapid pace, and hence reviewing becomes the critical path in ways it was never before. Reviewing AI-generated code requires a fundamentally different approach and cognitive abilities. A reviewer now gets a complete implementation to review that appears in minutes. They must understand the intent, validate assumptions that the AI coding assistant made, and verify the chosen integration patterns - all of this without the natural context that otherwise comes from watching the code evolve through iterations.
Testing Infrastructure
Meanwhile, your testing processes and infrastructure hit a capacity they were never designed for, the pace at which AI coding assistants generate code. And this has a domino effect - your test queues grow, developer context switch while waiting for results; test suites become a blocker as they can’t handle the commits coming in every few minutes.
Quality Validation
AI coding assistants generate code based on patterns they have observed in their training data, and it is often not in line with your business logic, edge cases specific to your domain, system-level interactions, or the infrastructure assumptions of how your Kubernetes deployments handle pods. These aren’t issues that cause production incidents; rather, these are precisely what AI wasn’t trained on.
Infrastructure Mismatch
This eventually highlights the weak points of your testing infrastructure, which weren’t designed for AI coding assistants. With the increased volume of code, you don’t only need to validate more code but also do it quickly and frequently. You need more integration tests to catch system-level issues that AI often fails to reason about, and more infrastructure tests because AI can make incorrect assumptions about your environment. And you need all of this without proportionally increasing your test infrastructure costs.
The reality is that the bottleneck hasn’t disappeared; it has just transferred.
Why Pipeline-Centric Testing Fails at AI Scale
CI/CD pipelines are one of those architectural decisions that seem obvious until they stop working. It made sense for years: test run when code is committed, quality gates ensured bad changes don’t reach production, and provided reproducibility.
But with AI-driven velocity, this same architecture creates bottlenecks that scaling alone can’t resolve.
Architectural and not Computational
The fundamental issue is architectural and not computational. Even with parallel execution within the pipeline, the pipeline itself operates sequentially. A code commit comes in, enters a queue, waits for an available runner, executes tests, aggregates results, and publishes artifacts. Each step happens in order.
This looks fine with say 30 commits per day, but when they increase to 200, these serial steps don’t just slow proportionally, they compound. What took only 5 minutes now takes 60 mins, not because tests run slower, but because of the increased queuing overheads.
Comprehensive End-to-end Testing
AI-generated code requires comprehensive end-to-end testing. Because it lacks system-level understanding of your infrastructure, it generates code that looks correct, but creates ripple effects across service integrations, creates race conditions, or worse, makes incorrect assumptions about your setup.
Catching these issues demands more extensive integration and E2E testing, which means longer test suites running through the same serial pipeline architecture.
Coupling Problem
Further, pipeline-centric testing couples test execution to code deployment. There’s an implicit assumption: to test something, you must deploy it through the pipeline. For example, an infrastructure change is made in a Helm chart. This doesn’t involve any application code, but it absolutely needs testing.
In a pipeline-centric mode, how do you trigger this test? Force a dummy commit? Manually execute the pipeline? Or maybe create a cron job to trigger the pipeline? All these scenarios share a common problem: the pipeline couples testing to deployment, and that coupling becomes a constraint when testing needs to happen independently of deployment frequency.
Observability Gap
Lastly, there’s the observability gap, which compounds all these issues. Each pipeline run creates isolated logs and artifacts. Want to understand why a test is flaky? You have to go through individual pipeline runs and manually correlate failures across commits.
Pipeline logs were designed to answer “did this run pass or fail?” and not to identify the execution patterns across test executions. Without centralized observability, teams lose the ability to understand the test executions, perform root cause analysis for failures or optimizations, or make data-driven decisions about test infrastructure investment.
One solution to all these problems would be to add more pipeline runners. Well, that addresses the problem, but not the structure. But they don't solve serial queueing, coupling constraints, or observability fragmentation. The solution requires rethinking the testing infrastructure entirely.
Continuous Testing as Infrastructure Evolution
One of the key things that needs to happen for continuous testing is shifting from reactive to proactive validation. Instead of executing tests when code commits, it should be triggered by code changes, infrastructure events, schedules, and policy checks. Tests run continuously, locally before committing, and produce consistent results regardless of execution context.
Orchestration Requirement
For continuous testing to happen, you need a flexible architecture to trigger your tests. You should be able to trigger test workflows not only through code commits, but also from infrastructure events when deployments complete, configuration changes, API calls for manual validation or incident response, scheduled runs, or in the event of policy changes when security scans detect issues requiring targeted testing.
This trigger flexibility decouples testing from deployment cadence. Infrastructure teams can validate their deployments without code commits. Security teams can configure policy checks without triggering test suites manually. Each test type can be automatically triggered based on when it is needed, not when the pipeline runs.
Execution Isolation & Parallelization
Each test workflow must run in isolation with explicit resource allocation to prevent resource contention and enable genuine parallel execution. In Kubernetes terms, this could be different jobs or pods with their own dedicated CPU, memory, and storage. This enables genuine parallel execution where tests don't compete for resources, test sharding where large suites are split across multiple runners, and environment-specific execution where tests run in namespaces matching their target environments.
Developers should be able run the same containerized test workflows locally that execute in CI/CD and production. The common execution engine guarantees that the same test produces identical results whether run on a developer's laptop, in your CI/CD pipeline, or in production infrastructure.
Unified Observability Layer
Centralized observability is key for successful continuous testing. A mature observability layer provides a centralized repository for everything from test artifacts and reports with structured storage and retrieval to trend analysis modules that help analyze and identify flaky tests before and track their performance trends. AI-assisted debugging recognizes patterns in failures and suggests fixes based on historical data.
This observability enables engineering leaders (and AI Agents!) to make data-driven decisions about test infrastructure investment, identify optimization opportunities, and understand test health across their entire system.
Practical Implementation using Testkube
Testkube is a Continuous Testing platform that bridges the gap between traditional pipeline-driven testing and a modern and event-driven testing approach for achieving deployment quality at scale. Testkube leverages Kubernetes infrastructure for running any kind of automated test at scale.
Testkube is framework-agnostic, which means it allows you to run any testing tool or script that your team is using, including popular tools like Playwright, Cypress, k6, JMeter, Postman, pytest, or any testing tool your team uses. Each Testkube executestest executes each test as a Kubernetes Job or Pod with explicit resource allocations and permissions, enabling fine-grained control and cost attribution.
Testkube provides multiple triggers that allow tests to be executed from CI/CD pipelines, Kubernetes events, scheduled cron jobs, API calls, or policy violation responses. The same test workflows run consistently everywhere, eliminating environment parity issues that cause "works on my machine" problems.
By being both vendor and trigger agnostic, Testkube acts as a centralized control plane that orchestrates tests across clusters and environments, providing unified visibility into testing activities regardless of where tests execute. And with Testkube MCP server integration, it enables AI coding assistants to generate, trigger, and analyze tests directly from AI-powered IDEs, closing the loop between AI code generation and AI-assisted validation.
Assessing Your Continuous Testing Maturity
Transforming your existing testing infrastructure to a continuous testing approach requires considering investments in terms of technical upgrades, people upskilling, and process changes. Thus, understanding where your organization stands from a maturity perspective helps prioritize investments and transformation timelines.
Most organizations fall into one of the three maturity levels listed below.
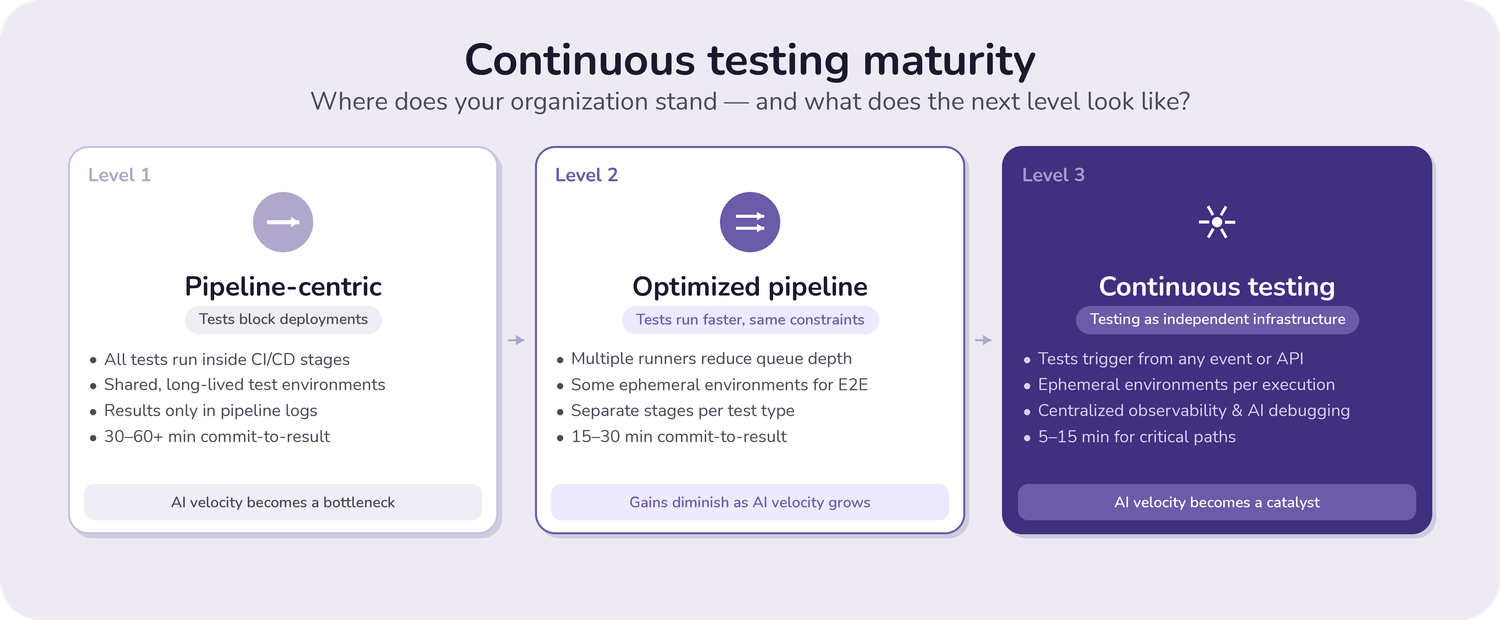
Level 1: Pipeline-Centric Testing
At this level, all your tests execute within CI/CD pipeline stages. Tests are tightly coupled to deployment workflows. Tests rely on shared, dedicated testing environments (dev, staging, QA) with heavy use of mocking to avoid environment conflicts and resource contention. Test results live only in pipeline logs, making debugging tedious and error-prone. Manual test execution requires triggering the entire pipeline, even for a single test.
Teams at this level experience AI velocity as a bottleneck. Code generation accelerates while the testing infrastructure is trying to keep up with it. The developer batch commits to avoid wait time and often switches to other tasks while waiting, and loses out on the context.
Level 2: Optimized Pipeline Testing
Teams at this level still use a pipeline-based testing, but are more refined and optimized. There are multiple runners that handle concurrent execution requests, reducing the queue depth. Some ephemeral environments are provisioned automatically for integration and E2E tests, though dedicated environments remain for baseline testing. There are separate test-stage runs for unit, integration, and E2E tests.
This provides improvement over level one; however, it remains fundamentally pipeline dependent. As AI code velocity increases, optimization gains diminish because the pipeline architecture remains the constraint.
Level 3: Continuous Testing Infrastructure
At this level, testing operates independently of deployment pipelines. Tests execute from multiple triggers: code commits, infrastructure events, schedules, API calls, and policy violations. Ephemeral, production-like test environments are provisioned on demand in Kubernetes for each test execution, eliminating environment contention and state pollution. Centralized orchestration control plane manages tests across clusters and environments. Unified observability surfaces test health across all executions. AI integration enables agents to generate, trigger, and analyse tests.
Level 3 teams experience AI code generation as a catalyst rather than a bottleneck. Tests are validated immediately. Feedback loops complete quickly. Code review focuses on design because testing validates implementation. Infrastructure changes trigger validation automatically.
Self-Assessment Questions
Where does your organization stand? Consider these indicators:
Building Your Continuous Testing Strategy
Transforming your testing infrastructure requires strategic investment, not just tactical changes. It should be a phased approach with clear investment and ROI for each stage.
Foundational Phase
The first thing that you must do before investing is to capture your current state and establish baseline metrics that will help justify your transformation and measure progress. Start by tracking lead time for changes, deployment frequency, mean time to recover (MTTR), and other metrics relevant to you.
Phase 1: Decouple Bottlenecks
Identify the isolated high-impact and critical test that shouldn’t block the pipeline. Tests that run post-deployment validation production, performance tests that require sustained resources, or integration tests that require a full production-like environment with real server dependencies.
Make use of Kubernetes jobs, for instance, that can be triggered post-deployment instead of pipeline stages. Measure the improvement in pipeline throughput and developer wait times.
Phase 2: Implement Test Orchestration
Deploy test orchestration infrastructure that provides centralized test catalogs, multi-trigger support beyond CI/CD, local execution capabilities matching CI/CD and production, and unified result reporting across contexts.
Such orchestration platforms allow teams to focus on test development rather than infrastructure management. Testkube's Kubernetes-native approach means tests execute in your infrastructure using your resources, giving you full control and avoiding vendor lock-in to proprietary runners.
Phase 3: Infrastructure Testing
Expand the scope of testing from application only to infrastructure as well. Implement Kubernetes manifest validation for Helm charts and deployment specs. Add Infrastructure-as-Code testing for Terraform, CloudFormation, or Pulumi templates. Include service mesh validation for traffic management and security policies. Integrate chaos engineering to verify resilience under failure conditions.
This helps catch issues AI-generated code creates through incorrect assumptions about your environment.
Phase 4: Enable AI Workflows
Close the AI loop with AI-assisted test orchestration in the long run. Generate tests from natural language descriptions. Automate test maintenance as code evolves. Implement intelligent test selection based on change analysis. Use AI troubleshoot failed tests and suggest remediations. Use pattern recognition for faster root cause analysis and anomaly detection.
AI agents interact directly with test orchestration through MCP Server integration, creating seamless workflows from code generation through validation and analysis.
Key Decision Points
- Build vs Buy: Building testing infrastructure requires dedicated platform teams. Purchasing orchestration platforms provides immediate capabilities with lower operational costs.
- Investment triggers: Invest when AI velocity creates measurable bottlenecks, for instance, when test infrastructure consumes over 20% engineering capacity, code review blocks deployments, or test-related incidents increase.
- Organizational structure: Continuous testing requires cross-functional collaboration. QA teams own test logic and maintenance. Platform teams manage testing infrastructure and orchestration. Security teams contribute policy and compliance tests. Application teams own domain-specific integration tests.
Next Steps: Make Testing Your Strategic Advantage
Every engineering team has access to similar AI coding assistants. GitHub Copilot, Cursor, and Claude are widely available. Hence, competitive advantage won't come from generating code faster - it comes from validating faster.
Organizations that implement continuous testing infrastructure ship AI-generated features with confidence at higher velocity. They reduce incident rates through comprehensive validation, along with lower infrastructure costs through efficient resource allocation rather than overprovisioning pipeline runners.
Use the maturity framework to identify where your organization stands. Measure your current bottlenecks and understand how long developers wait for test results. What's the cost of test infrastructure versus the velocity gained?
Connect with the Testkube team to explore how continuous testing orchestration can enable sustainable AI-assisted development for your teams.
About Testkube
Testkube is the open testing platform for AI-driven engineering teams. It runs tests directly in your Kubernetes clusters, works with any CI/CD system, and supports every testing tool your team uses. By removing CI/CD bottlenecks, Testkube helps teams ship faster with confidence.
Get Started with a trial to see Testkube in action.


