

Table of Contents
Start your free trial.
Start your free trial.

Start your free trial.



Table of Contents
Executive Summary
AI-assisted development has reduced the time between idea and implementation. Tools like GitHub Copilot, Cursor, Claude, and workflow automation platforms such as n8n can now generate application code, infrastructure manifests, and pipelines almost instantly, refined through prompts. The challenge now is achieving the same velocity with confidence that this code is correct, secure, and ready for production.
When an AI coding assistant generates a complex Kubernetes deployment in seconds, how confident is your developer that it adheres to security policies, handles edge cases, or won't buckle under production load? Traditional human code review simply cannot keep pace with the sheer volume of AI-assisted development.
Adoption of an AI coding assistant is inevitable. Recent data from the 2025 Stack Overflow Developer Survey reveals that 84% of developers have now integrated AI into their workflows, yet a staggering 46% actively distrusts the output. The real task now lies in building verification systems that match AI's speed while maintaining the rigor required for enterprise software. This is precisely where continuous testing becomes essential. It adds an automated and non-negotiable verification layer that makes AI-generated code trustworthy.
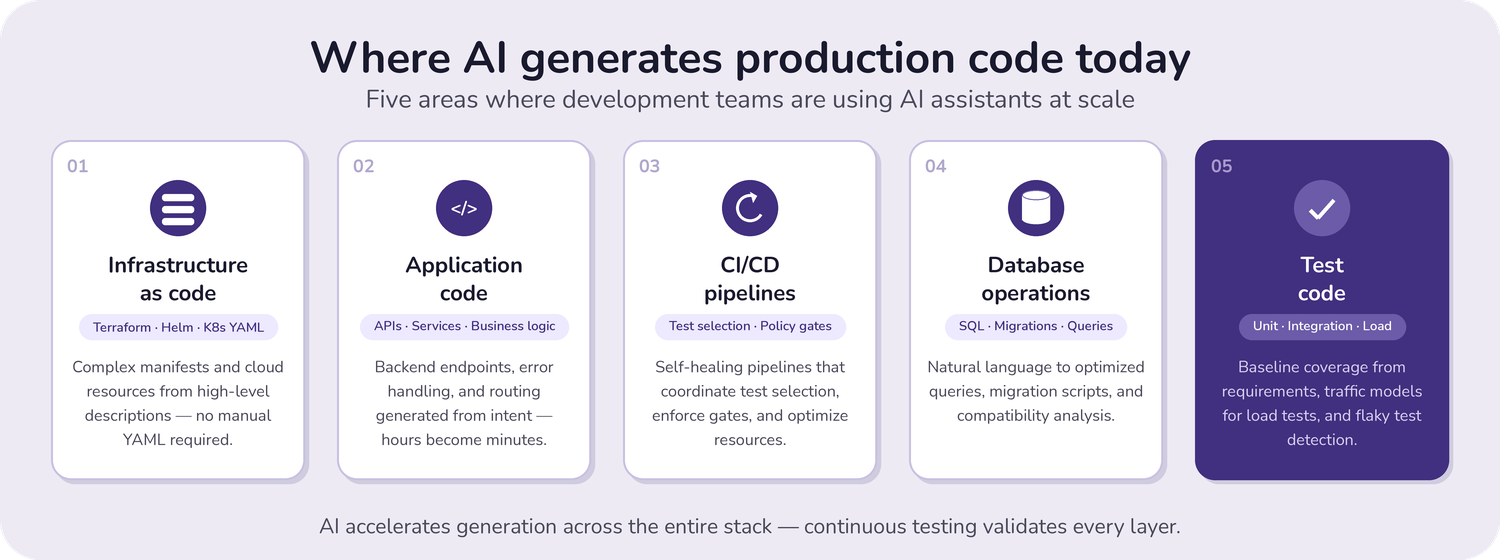
AI Code Generation in Practice: What Developers Are Building
AI-assisted development has moved beyond IDE autocomplete and helper snippets. Today, developers use AI tools to generate production-facing code across the entire software delivery stack.
Infrastructure-as-Code
Developers are using AI to bridge the gap between ClickOps and automated provisioning. AI now generates complex Terraform modules, Kubernetes (K8s) YAML manifests, and Helm charts directly from high-level architecture descriptions. Developers can now deploy entire business applications without manually writing K8s YAML by using AI-driven Terraform providers.
Application Code
Building backend services has shifted toward intent-based development. Developers use AI to generate boilerplate for REST and GraphQL endpoints, including the underlying business logic, error handling, and routing in hours rather than days.
CI/CD Pipelines
AI is turning CI/CD from a bottleneck into a self-healing process. Beyond log analysis and root-cause diagnosis, agentic CI/CD systems reason for what to build, what to test, and when to promote changes. Modern pipelines increasingly use AI to coordinate test selection, enforce policy gates, manage environment drift, and optimize resource usage across builds and deployments.
Database Operations
Developers use tools for Text-to-SQL to translate natural language into optimized queries across SQL and NoSQL databases. AI is used to draft migration scripts, reason for data transformations, and surface compatibility issues, while execution and validation remain controlled by existing database tooling.
Test Code
AI is increasingly used to generate test code alongside application logic. Developers rely on AI to produce unit and integration tests from functional requirements, establishing baseline coverage quickly. AI is also used for load and stress testing by generating traffic models and identifying performance risks under scale. It helps detect flaky tests and prioritize test execution based on recent changes.
The Trust Gap: Challenges with AI-Generated Code
The surface-level correctness is what makes AI-generated code dangerous. As it moves faster through delivery pipelines, a widening trust gap emerges between what looks correct and what is safe, secure, and production ready.
Here are the five critical failure points:
Hidden Logic Flaws
AI code often passes the "eye test" because it is syntactically perfect, but it can be semantically disastrous.
The "Hallucinated" Business Logic
Because it was not trained on them. It infers behavior from publicly available patterns and common implementations. Small semantic assumptions like using `>` instead of a `>=` in a critical financial calculation can pass a quick review but lead to incorrect balances, failed reconciliations, or regulatory exposure once deployed.
Missing Edge Cases
LLMs are trained on the happy path. They frequently overlook rare failure modes (like race conditions or partial database rollbacks) that aren't prominent in their training data. A perfectly functional database query might violate your data access governance rules. A certain API endpoint might expose personally identifiable information in ways that conflict with GDPR requirements.
Security Blindspots
AI models are trained on large volumes of public code, including repositories that demonstrate insecure or suboptimal practices. As a result, generated code may reproduce unsafe patterns such as improper secret handling, insecure defaults, insufficient input validation, or inefficient resource usage that can lead to memory leaks. These issues often pass initial review because the code is syntactically correct and appears functionally reasonable.
Insecure Patterns
AI-generated code might construct file paths directly from user input without validation, creating path traversal vulnerabilities. It understands syntax but doesn't inherently grasp the security implications of how data flows through systems. A critical vulnerability in CodeRabbit's production infrastructure was identified. It allowed remote code execution through a malicious pull request, ultimately providing access to API tokens, secrets, and potential read/write access to over 1 million code repositories, including private ones.
Training Data Contamination
AI models learn from millions of public repositories, many of which contain poor security practices and use these anti-patterns as "valid" code examples. Generated code that might include hard-coded credentials embedded directly in source files, SQL injection vulnerabilities in database queries, or dependencies with known CVEs that were common in the training data timeframe.
Inconsistent Quality
The unpredictability of AI-generated code quality creates a unique challenge for development teams:
Non-Deterministic Outputs
AI outputs can vary across runs, sessions, and model versions. Updates to the underlying LLM can significantly change generated code or logic, even for identical prompts. Over long interactions, this can lead to lost context, architectural drift, and contradictions within the same codebase. This poses a serious risk for automated agents and CI-driven workflows that rely on consistent behavior.
Non-Idiomatic Patterns
AI-generated code might technically work, but fail to follow language-specific best practices or your team's coding standards. A Python function might use Java-style verbose error handling instead of Pythonic exception patterns. A React component might use outdated class-based syntax instead of modern hooks. The code functions, but creates maintenance debt and confusion for developers expecting idiomatic implementations.
The Black Box Effect
When developers write code manually, they develop a deep understanding through the process of implementation. Every decision, every edge case consideration, every architectural choice becomes part of their mental model. With AI-generated code, that understanding is often shallower.
Shallow Understanding
Developers know what the code does at a surface level but may not fully grasp the reasoning behind specific implementation choices. Why did the AI choose this particular error handling pattern? What assumptions were made about input validation? This knowledge gap becomes critical when something goes wrong.
Debugging Challenges
When something goes wrong, developers lack the context they would have gained through manual implementation. Over time, these knowledge gaps compound, leaving teams maintaining increasingly complex codebases they don't fully understand.
The Scale Problem
Teams are shipping more code faster, but with higher defect rates that overwhelm traditional review processes.
Review Capacity Crisis
AI-generated pull requests are already overwhelming human review capacity. The State of the AI vs. Human Code Generation Report, based on an analysis of 470 open-source pull requests, found that AI-generated PRs contained 1.7× more issues than human-written code. More concerning, high-issue outliers were significantly more common in AI PRs, creating review spikes that teams cannot manage consistently. Manual code review does not scale to this volume.
The False Choice
Teams are pushed into an artificial trade-off: slow down AI-assisted development to preserve review quality, or reduce review rigor to maintain velocity. Neither option is acceptable. Slowing down eliminates the very advantage that makes AI code generation valuable. Accepting elevated risk invites production incidents, security breaches, and long-term technical debt. At AI velocity, this is not a people problem; it is a systems problem.
These flaws are subtle. They don’t trigger compilation errors or obvious failures. They pass human review because the logic appears reasonable, only to surface later as production bugs that are difficult to trace back to their origin.
The Solution: Verification Through Continuous Testing
AI code generation and continuous testing are complementary. AI accelerates code creation; testing verifies correctness. Prompt and context engineering can improve the quality of AI-generated code at the source. Supplying business rules, architectural constraints, configuration schemas, and repository-specific patterns helps reduce certain classes of errors. This improves the baseline, but it does not remove the need for validation.
Even with well-crafted prompts, AI lacks awareness of environment-specific edge cases, regulatory constraints, and real production behavior. Context can guide generation, but it cannot replace verification.
Why Continuous Testing Specifically?
Continuous testing provides several critical advantages for AI-generated code:
- Fast Feedback Loops: Tests execute immediately as code is generated, validating behavior before developers move on. This leads to the correct shift-left, where failures are caught early, and AI can regenerate corrected code while context is still available, keeping iteration tight and controlled.
- Multi-Layered Validation: Different test types surface different classes of issues. Unit tests validate logic, integration tests verify service contracts, security scans detect vulnerabilities, and performance tests expose scaling limits. This layered approach matches the breadth of risks introduced by AI-generated code.
- Automated Enforcement: Test results act as enforced quality gates rather than advisory signals. When validation fails, pipelines stop automatically, preventing flawed code from progressing. This removes subjective human judgment from critical safety decisions at AI speed.
Testing Across the Development Lifecycle
Effective continuous testing of AI-generated code spans the entire development lifecycle, with validation applied at each stage.
- Development Phase: Unit tests validate basic logic and syntax immediately after generation. Failures surface while AI context is still available, enabling fast regeneration before code is committed. Pre-commit component or E2E tests provide early validation that AI-generated code could not break like system boundaries or constraints.
- Pull Request Gates: Pre-merge test suites enforce logic correctness, security controls, and API contracts. Security scans detect hard-coded credentials, leaked secrets, and unsafe patterns, while static analysis enforces consistency and quality standards before code enters the main branch.
- Staging Deployment: Event-driven integration and performance tests run in production-like environments to validate behavior with real configurations, data, dependencies, and concurrency. This stage surfaces error-handling and scaling issues before user impact.
- Production Smoke Tests: Post-deployment tests verify critical paths against live dependencies and traffic patterns. Policy violations or regressions trigger targeted validation to prevent cascading failures.
This lifecycle-aligned approach applies established testing principles to the realities of AI-generated code, where verification must operate continuously and at scale. For a deeper understanding of how these patterns apply in cloud-native systems, see Testing Strategies for Microservices.
Testkube: Test Orchestration for AI-Generated Workloads
Building and maintaining this testing infrastructure is complex. Different test types require different tools, runners, and reporting mechanisms. Integrating them into CI/CD pipelines, collecting results, and providing visibility to different stakeholders becomes a full-time engineering effort.
Testkube provides:
Vendor agnostic orchestration of any testing tool or script at scale: Testkube leverages Kubernetes to ensure consistent test results across local, ephemeral and long-living testing environments. It is regardless of if tests were triggered manually, from a CI/CD pipeline, on a schedule or based on an infrastructure event. You can scale tests through parallelization, sharding, and matrix testing, which is essential for managing high-volume AI workloads.
Centralized Visibility with AI-Powered Troubleshooting: Testkube aggregates logs, metrics, artifacts, and results across all test executions into a single view. AI-assisted analysis compares runs, highlights failure points, and summarizes root causes, removing the need for manual log inspection. Natural language workflow discovery allows users and AI agents to query executions directly (for example, “find all failed Playwright tests”), enabling faster diagnosis, consistent understanding across teams, and reliable troubleshooting at AI velocity.
Deep integrations with existing tools and infrastructure: Testkube integrates seamlessly with existing collaboration tools, incident management platforms, and business intelligence systems such as CI/CD Tooling, GitOps Tooling, Observability, and Workflows. Tests can trigger automatically on infrastructure updates, code commits, or policy violations. Testkube can orchestrate multiple test types like unit, integration, security, and performance without manual setup for different stages of development.
Testkube MCP Advantage: Through the Model Context Protocol (MCP) Server, Testkube enables AI agents to execute, observe, and manage tests directly from development environments such as VS Code and Cursor. AI agents can run test workflows, navigate execution history, and create or update test resources as part of multi-step, agent-driven workflows. By integrating with other MCP servers like GitHub MCP and Playwright MCP, Testkube MCP connects code, tests, and execution into a single, verifiable loop, allowing AI-assisted development to include continuous validation, automated debugging, and enforced testing before code progresses.

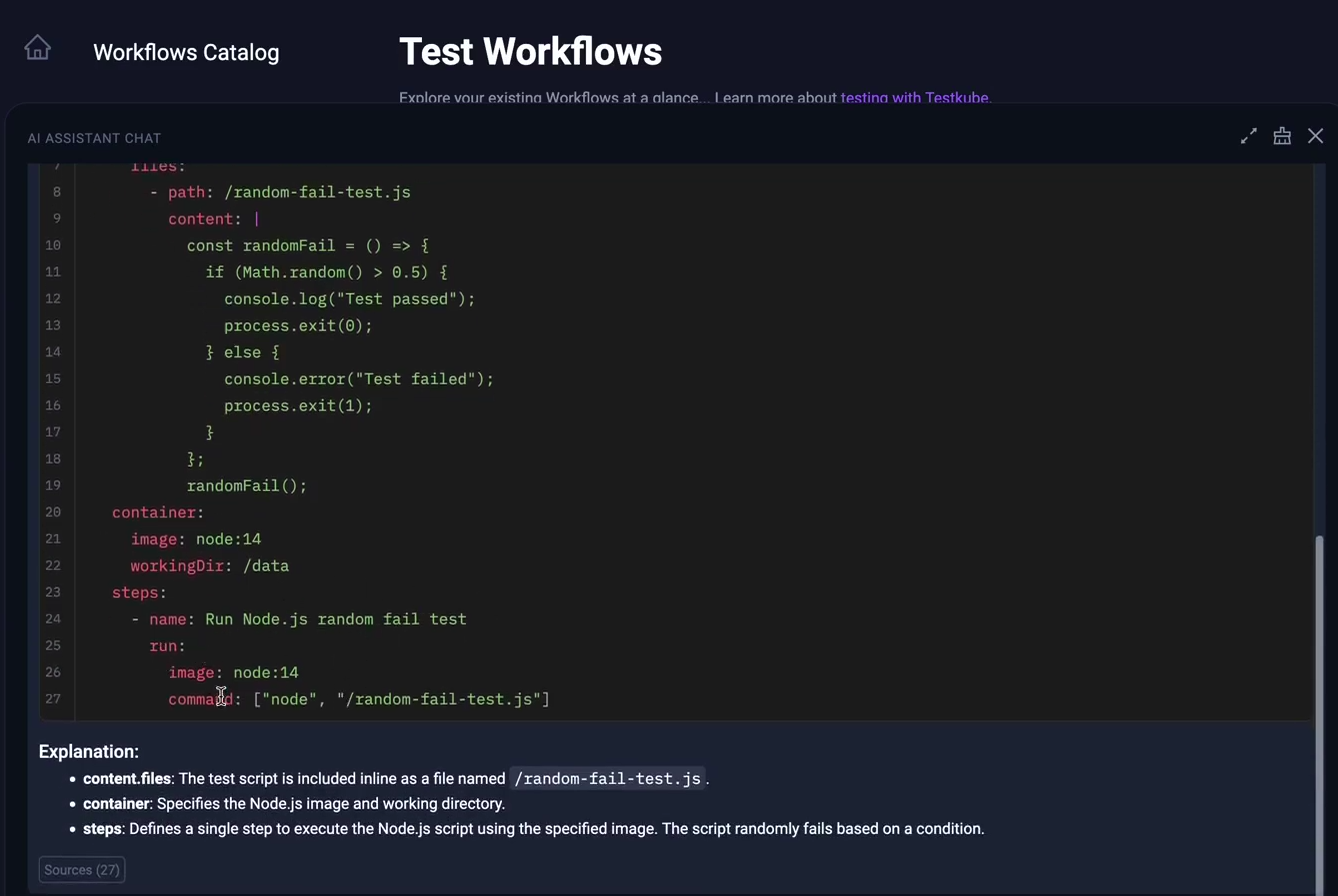
Automated Test Workflows Generation with AI Assistant: Developers can use conversational AI to generate, optimize, and troubleshoot YAML configurations of Test Workflows for any testing tool or framework. For example, you can use AI to create workflows that would fail randomly to test a new workflow feature, rather than relying on existing 100% successful workflows.
Taken together, these features enable reliable, scalable testing in environments where AI-generated code and workflows are constantly changing. Testkube acts as a stable orchestration layer that keeps tests observable, repeatable, and tool-agnostic as teams adopt AI at scale.
Conclusion
AI code generation accelerates development, but acceleration without verification creates risk. The organizations succeeding with AI are validating AI-generated code the fastest.
A Continuous Testing approach across the entire SDLC provides that mandatory validation layer. Multi-layered automated tests catch logic flaws, security vulnerabilities, and policy violations before they reach production. Modern test orchestration platforms like Testkube make this validation practical at scale, eliminating the overhead of building custom automated test orchestration and observability solutions.
The future closes the loop completely: AI generates code, AI generates tests, and automated orchestration validates both. This isn't theoretical; tools like Testkube MCP make it real today. The question isn't whether your team will adopt AI-assisted development. The question is whether you'll build the verification infrastructure to make that adoption trustworthy.
About Testkube
Testkube is the open testing platform for AI-driven engineering teams. It runs tests directly in your Kubernetes clusters, works with any CI/CD system, and supports every testing tool your team uses. By removing CI/CD bottlenecks, Testkube helps teams ship faster with confidence.
Get Started with a trial to see Testkube in action.


