

Table of Contents
Start your free trial.
Start your free trial.

Start your free trial.



Table of Contents
Executive Summary
CI/CD pipelines are good at running through a set of predefined steps. They move artifacts through stages, run tests, and let us know if things pass or fail. For a long time, that was all we really needed.
But that's just not the case anymore.
AI-assisted coding has dramatically increased code velocity. Developers ship changes faster, triggering more tests across more environments, clusters, and configurations. Testing has moved way beyond the old execution model. Tests run all the time, not just when someone pushes a commit. Failures can pop up in places the pipeline never even sees, sometimes long after the workflow is done. And when something does break, that red build doesn't really help us figure out what actually went wrong or what to do next.
Most teams try to fix this by piling on more complexity: more conditional logic, more webhooks, more scripts to parse logs and send alerts. Before you know it, the pipeline turns into a patchwork of glue code, and every new change feels riskier than the last.
But this isn't really a tooling problem, it's an architectural one. Pipelines were built to execute workflows, not to actually reason about them.
The gap between execution and understanding
When a test fails, the real question isn't just "did it pass?" It's "why did it fail, does it matter, and what should we do next?"
To answer that, we need context. What changed in the code? Has this test failed before? Is it just this environment? Are other tests showing the same thing? What do the logs actually say?
Pipelines just don't have access to that kind of context, and even if they did, they can't make sense of it. They're built to report outcomes, not to analyze them.
So what happens? Engineers end up doing all this manually by digging through logs, comparing runs, checking environment configs, and eventually coming up with a theory. Multiply that by every failure across every team, and suddenly you've got a huge drag on velocity that no amount of pipeline optimization can fix.
From execution to reasoning
Agentic test orchestration flips the script. Instead of trying to encode every possible decision into pipeline logic ahead of time, you let agents observe what's happening, reason over the context, and help you decide what to do next.
This isn't about replacing pipelines, it's about finally handling the parts of orchestration that pipelines just weren't built for.
An agent can look at a failed test, pull in logs and artifacts, check past results, and figure out if it's a flaky test, an environment issue, or a real regression. It can decide whether to rerun, escalate, or connect the dots with other failures. Instead of flooding your channels with alerts that need a human to interpret, it can actually surface what matters.
Consider what troubleshooting looks like today. An engineer might spend 20 minutes correlating logs across three services, checking environment configs, and comparing against previous runs just to form a hypothesis. An agent with access to that same context can surface the likely root cause in seconds, freeing engineers to fix the problem instead of hunting for it.
That difference really matters. With static orchestration, you have to try to predict every scenario and encode it all up front. Agentic orchestration adapts as it goes, based on what it actually sees. One scales with complexity, the other just makes it harder.
What makes this practical
Agentic workflows sound great in theory, but in practice, they only work if agents are built into a system that truly understands testing.
Generic agent frameworks can automate tasks, but they don't have native access to test workflows, execution engines, or historical results. You end up building and maintaining custom integrations just to give agents the context they need. And desktop-based AI assistants? They're fine for individual developers, but they just don't scale to shared clusters, team workflows, or production-grade observability.
For agents to actually reason about quality, they need three things: a reliable way to communicate with testing systems, a centralized view of test workflows and execution, and observability across runs and time. That foundation is what makes agentic orchestration viable, not solely the agents themselves.
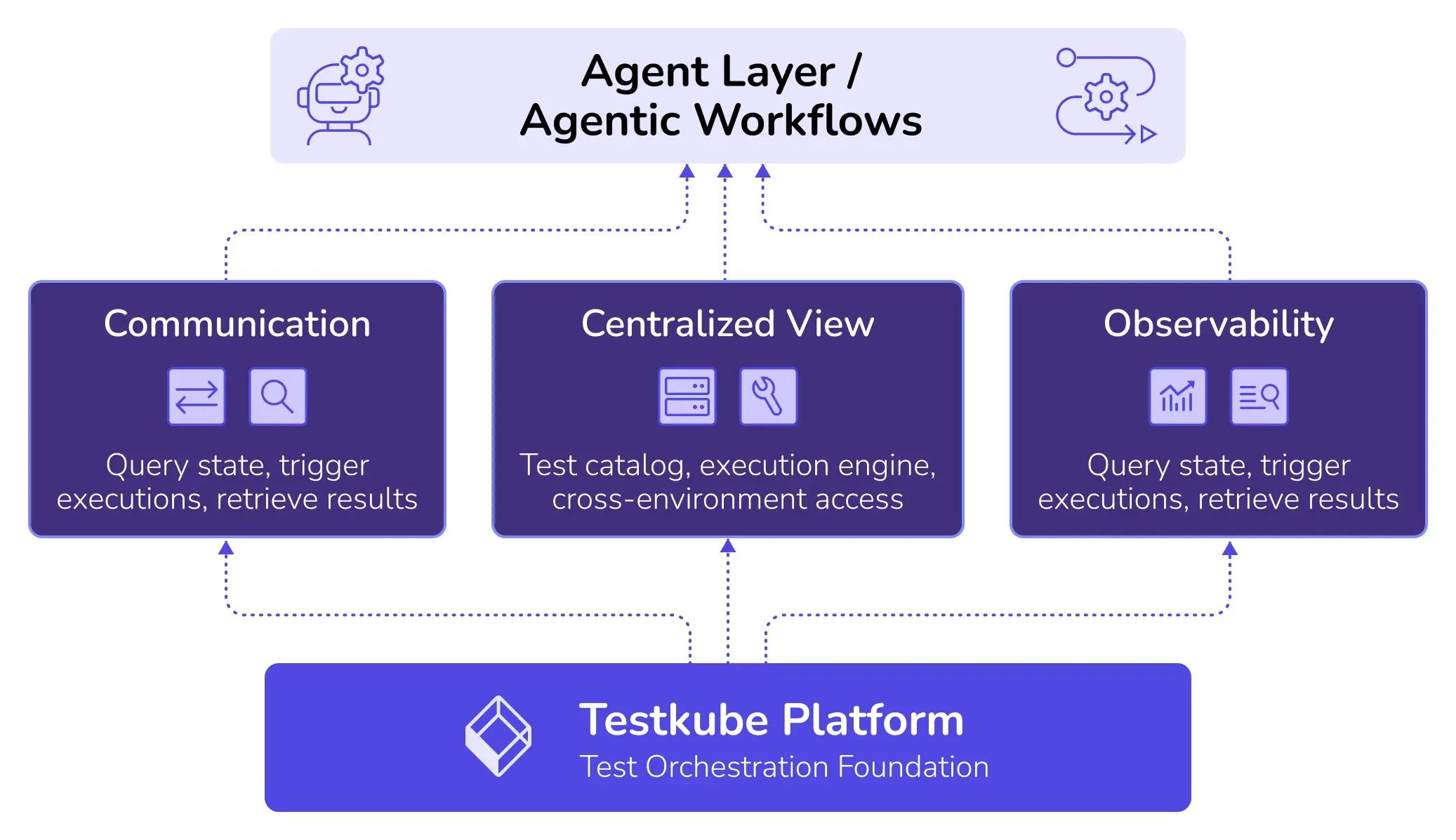
This is the infrastructure layer that makes agentic orchestration practical. Without it, you're just adding another integration to maintain.
Where this is headed
This is exactly what we’re working on at Testkube. With our January release, we’re introducing a native AI Agent Framework that is deeply integrated with our continuous testing platform. This means AI Agents can tap into the same context, results, and insights your team already uses, so they can actually help you reason about quality. Since agents are built into a quality-aware platform, there’s no need for custom integrations or piecing together context from scratch. Everything works together in the same unified view your team already trusts. And should you want to pull in context or tools from external systems like Grafana, GitHub or DataDog, Testkube AI Agents can make full use of these platforms MCP Servers to enrich their context and your testing experience.
To give you an idea of where this is all heading, we’ve outlined three sample use-cases where AI can make a (huge) difference: advanced troubleshooting and failure analysis, automated remediation, and enhanced AI-generated context. These are all workflows where agents can take busywork off your plate and help you spot what matters faster, without needing your team to map out every possible scenario ahead of time.
As testing gets more continuous and systems become less predictable, this shift feels inevitable. Orchestration can’t just be about running steps anymore; it needs to actually understand what’s happening and why.
Alerts tell you something happened, but agents help you figure out what to actually do about it.
About Testkube
Testkube is the open testing platform for AI-driven engineering teams. It runs tests directly in your Kubernetes clusters, works with any CI/CD system, and supports every testing tool your team uses. By removing CI/CD bottlenecks, Testkube helps teams ship faster with confidence.
Get Started with a trial to see Testkube in action.
.png)

