

Table of Contents
Start your free trial.
Start your free trial.

Start your free trial.



Table of Contents
Executive Summary
Software teams spent years obsessing over pipeline speed. The goal was to move a commit from a developer laptop to a production server as fast as possible, and over time that number got impressively small. Then AI coding assistants arrived, and the slowest step, writing the code itself, effectively disappeared. The bottleneck did not vanish, though. It moved into continuous validation, and teams now write code faster than their validation systems can verify it. The question shifted from "Can we ship faster?" to "Do we still understand what we shipped?"
This post explains why traditional testing pipelines were not designed for this reality, why AI-generated code demands a different approach to validation, and how to build a continuous validation loop: a system that does not just check code at deployment but observes, verifies, and learns from it in production. It also covers how Testkube fits into that architecture across test orchestration, runtime validation, and feedback-driven quality engineering.
Why AI broke the traditional testing rhythm
Code is no longer the slowest part
The traditional software pipeline had a natural pacing. Code took time to write, which gave QA time to prepare and infrastructure time to plan. Those rhythms kept everything roughly synchronized. AI removed that synchronization almost overnight.
Implementations that used to take days are now generated in seconds. The volume of changes hitting review queues has grown sharply, but the human bandwidth to review them has not. Teams are approving more code with less context per change, and QA systems built for a slower cadence cannot handle the throughput. Development velocity has outpaced validation maturity, and that gap is now an operational risk. We covered the early symptoms of this shift in why AI writes code faster than teams can test it.
Releases became continuous experiments
Before AI-generated code was common, a release represented a defined set of deliberate decisions. Engineers knew, roughly, what changed and why. That predictability made testing tractable.
AI-generated systems do not work that way. Because generative systems are non-deterministic, even small prompt variations can lead to different reasoning paths, tool selections, or outputs. Implementations vary across iterations even for similar inputs. Production becomes the first place where unknown behavior patterns appear, which is precisely where you least want to discover them. Every release now sits closer to an experiment than a controlled deployment, and static test plans cannot anticipate the shape of the next one.
Validation cannot stay event-based
Traditional testing is event-driven. You run tests when code is committed, when a build finishes, or when a deployment happens, and between those events the system is assumed to be stable. That assumption no longer holds for AI-generated implementations, which may vary each time code is regenerated.
Changes to prompts, models, or generation workflows can produce materially different implementations, which makes reproducibility and validation harder. Continuous validation addresses this by extending verification beyond the CI pipeline through smoke tests, synthetic transactions, canary validations, production monitoring, and real-user feedback. Instead of validating software only at release boundaries, these mechanisms measure behavior continuously as systems are deployed and used. Quality assurance stops being a checkpoint and becomes a continuous feedback loop, where every deployment, runtime signal, and production incident contributes to improving future implementations.
Why AI-generated code needs adaptive validation
Generated code is not fully deterministic
Human-written code is deterministic in a straightforward sense: the same engineer writing the same function twice produces nearly identical logic. AI-generated code does not share this property. Similar prompts can produce different implementations, and the same codebase, regenerated after a model update, may behave differently even when the prompts have not changed.
This makes traditional regression testing harder to apply. Validation baselines cannot be set once and held static; they need to evolve with the system. Ensuring consistency across iterations is no longer something a team can do manually at scale. The real task is building verification systems that match AI's speed while keeping the rigor enterprise software requires.
Traditional regression testing has blind spots
Static test suites are designed to verify known behavior. They are built from known scenarios, known edge cases, and known failure modes. AI-generated code expands the surface area of potential behavior faster than any team can write tests to cover it. Edge cases multiply, new execution paths appear between test cycles, and runtime failures escape pre-production validation, not because the tests were poorly written but because the behavior they needed to catch had not been anticipated. This is the same blind spot that lets AI code pass unit tests but break in production.
Behavioral drift is particularly insidious because it does not announce itself. It accumulates gradually as the system evolves, and by the time a static suite notices, the gap between expected and actual behavior is already significant.
Security and compliance shift continuously
AI-generated code introduces security and compliance challenges that traditional review processes were not designed to handle. As generation speed increases, manually inspecting every generated artifact becomes impractical. Vulnerabilities, insecure configurations, dependency risks, and policy violations can be introduced at the same pace code is produced, which makes periodic security reviews insufficient.
Security and compliance validation therefore have to become continuous rather than event-based. Policy checks, security scans, compliance controls, and runtime verification need to run alongside functional service validation throughout the delivery lifecycle. Instead of treating security as a single gate before deployment, teams need workflows that continuously verify generated applications remain secure, compliant, and aligned with organizational standards as they evolve.
Continuous validation as a system capability
Validation moves beyond CI pipelines
The typical CI pipeline ends at merge or deployment. Continuous validation, as a system capability, does not. It extends into the runtime environment and treats production as part of the testing lifecycle.
This is a meaningful architectural shift. Testkube's approach to continuous validation operates independently of traditional CI/CD systems and continues after deployment rather than stopping at the delivery gate. Production environments generate validation signals constantly. The question is whether your systems are collecting and acting on them.
Observability becomes a validation input
Logs, metrics, and traces have traditionally belonged to monitoring and incident response. In a continuous validation architecture they serve a second function: they are behavioral evidence.
Runtime telemetry reveals execution patterns that pre-production testing cannot simulate. Metrics surface silent regressions, degradations in behavior that do not trigger explicit errors but represent meaningful deviations from expected performance. Distributed traces, including those gathered through OpenTelemetry, expose unstable execution paths that only emerge under real traffic. Connecting observability output to validation workflows turns passive monitoring into active verification, and centralized test observability is what makes those signals usable across teams.
Feedback loops replace static gates
The most significant shift in continuous validation is conceptual. A failed test is no longer only a signal to block a deployment; it is a learning input. Production incidents become data points that improve future code generation, and systems can evolve through operational feedback rather than requiring teams to manually identify and patch behavioral gaps.
This feedback path, from validation failure to prompt refinement to improved generation, is what turns continuous validation into continuous learning. The goal is not only to catch more bugs faster. It is to build a system that gets systematically better at producing reliable behavior over time.
How to build the continuous validation loop
The loop has three stages: generate, validate, and learn. Each one feeds the next. The table below contrasts the event-based model most teams start with against the continuous model the loop produces.
Generate
AI creates code, infrastructure configurations, test scaffolding, and deployment manifests. These generated artifacts move directly into automated workflows without manual handoffs. Prompt engineering becomes part of the delivery lifecycle in a concrete way, because the quality of prompts directly determines what enters validation. Generated outputs need traceability: you need to know which prompt, which model version, and which context produced a given artifact in order to reason about failures later.
Validate
Validation extends beyond traditional test execution to continuously verify that generated code behaves as intended in real environments. Unit tests, integration tests, policy checks, security scans, and service validations run to detect regressions across code, infrastructure, and configuration changes. Instead of relying on periodic test cycles, validation runs throughout the delivery lifecycle, measuring runtime behavior, resilience, and operational correctness across multiple environments. Success is determined not only by whether a build passes, but by whether the system keeps performing reliably under real-world conditions. Teams that need to handle a sharp rise in pull requests can find concrete tactics in our guide to scaling testing for AI-accelerated development.
Learn
Learning turns validation results into inputs for the next generation cycle. Test outcomes, failure patterns, production incidents, and operational feedback provide insight into how generated implementations behave in real-world conditions. These signals help refine prompts, improve generation workflows, strengthen testing strategies, and identify recurring sources of defects. Instead of treating failures as isolated events, the system captures and reuses them as knowledge, continuously improving the quality of future AI-generated code and infrastructure.
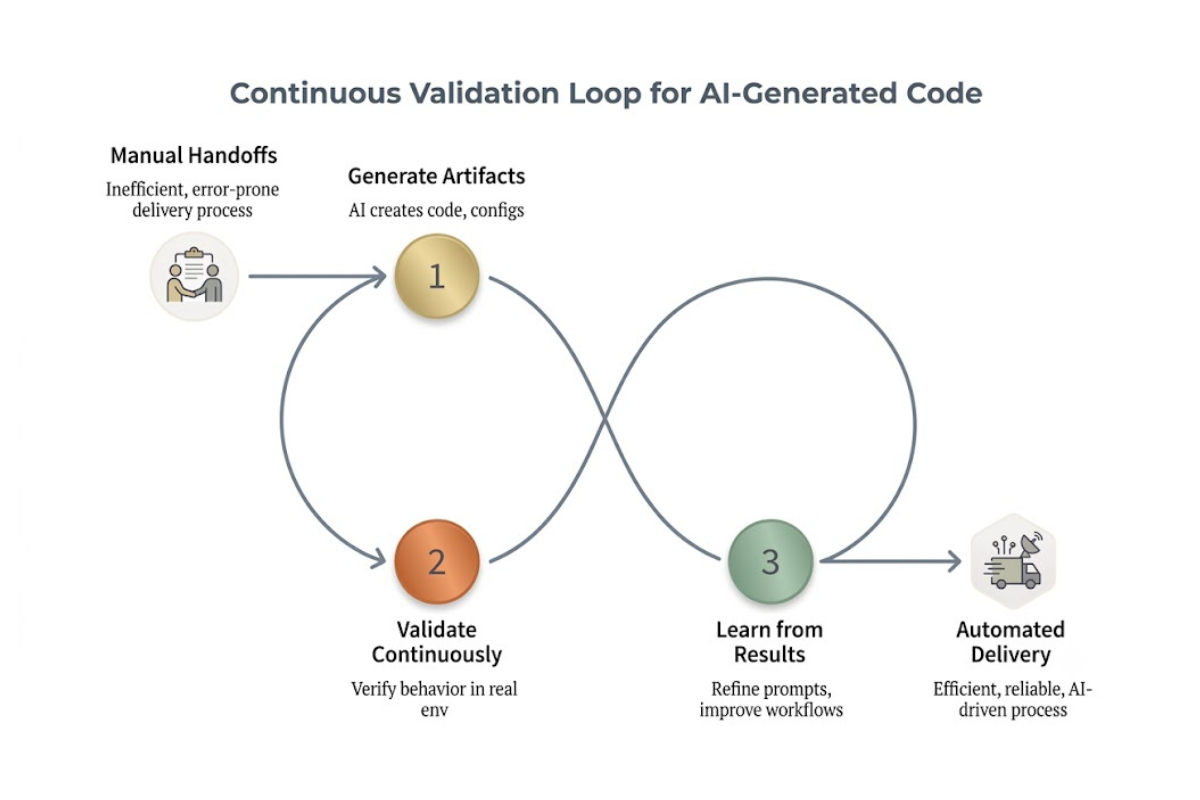
How Testkube enables the continuous validation loop
Test orchestration across dynamic environments
Testkube executes tests directly in Kubernetes environments, which means test execution lives in the same infrastructure as the application rather than in a separate, external system. It supports distributed validation across multiple environments and integrates with AI-driven delivery pipelines. Complex testing stages such as functional, load, security, and compliance orchestrate through a single workflow layer. Teams use this to run comprehensive validation at scale across clusters without rewriting existing test suites.
Continuous validation beyond CI
Testkube extends testing into runtime and operational environments, not just CI pipelines. Event-driven validation workflows trigger tests in response to infrastructure changes, configuration updates, or behavioral anomalies, not only code commits. This makes it possible to run validation continuously rather than periodically, treating the production cluster as an active testing surface rather than a passive target.
Feedback-driven quality engineering
Testkube connects test executions with aggregated observability signals over time, which is the technical mechanism behind the feedback loop described above. Teams get earlier visibility into regressions because validation is tied to runtime behavior rather than only pre-deployment checks. The same execution context is also available to AI agents through the Testkube MCP Server, so operational insights inform testing strategies iteratively. The result is visibility into how system behavior evolves over time, plus the data to act on that evolution systematically.
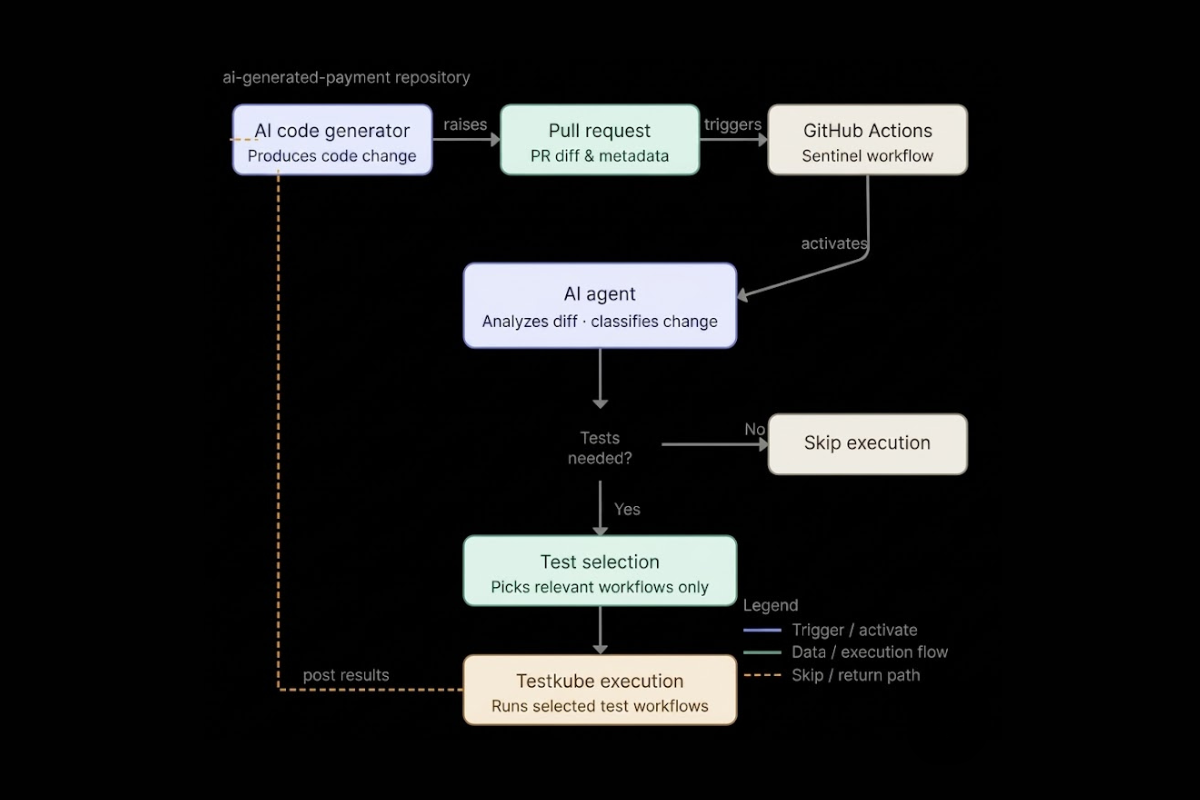
Key takeaways
- The bottleneck moved from writing code to validating it. AI generates implementations in seconds, so verification, not authorship, is now the constraint on safe delivery.
- AI-generated code is non-deterministic. Similar prompts and model updates can change behavior, which breaks static regression baselines and forces validation to evolve with the system.
- Event-based testing leaves runtime gaps. Continuous validation extends verification into production using smoke tests, synthetic transactions, canary checks, and observability signals.
- The loop has three stages: generate, validate, and learn. Each failure and production signal becomes an input that improves the next round of generation.
- Testkube runs the loop in real environments. Kubernetes-native execution, event-driven triggers, and observability-linked results turn continuous validation from a concept into infrastructure.
Frequently asked questions
About Testkube
Testkube is the open testing platform for AI-driven engineering teams. It runs tests directly in your Kubernetes clusters, works with any CI/CD system, and supports every testing tool your team uses. By removing CI/CD bottlenecks, Testkube helps teams ship faster with confidence.
Get Started with a trial to see Testkube in action.


